1.【开篇】用知识去对抗技术不平等
推荐系统从搜索引擎借鉴了不少技术和思想,比如内容有就来自由Amazon发扬光大的,基于用户(User-based)和基于物品(Item-based)的协同过滤将推荐系统技术从内容延伸到协同关系,超越了内容本身。
后来 Netflix 搞了一个瓜分百万美元的土豪比赛,以矩阵分解为代表的评分预测算法如雨后春笋般出现。至此,机器学习和推荐系统走得越来越近,最近十年,深度学习和强化学习又将推荐系统带向了新的高度。
推荐系统也是现在热门的 AI 分支之一,但凡AI类的落地,都需要具备这几个基本元素才行:数据、算法、场景、计算力。推荐系统也不例外。有一个趋势我是确信无疑的:世界在向网状发展,万事万物倾向于相互连接构成复杂网络。复杂网络具有无尺度特点,表现是:少数节点集聚了大量连接。这个现象不陌生,叫做马太效应,社交网络粉丝数、网页链接引用量、电商网站商品销量等等,无不如此。推荐系统的使命,就是要用技术来对抗这种不平等。
一个推荐系统如何才能从 0 到 1 诞生,这需要去了解哪些知识
- 能解决系统起步阶段 80% 的问题
- 已被无数产品验证过有用的东西
- 遇到问题能够找到人或者社区交流,而非曲高和寡的前沿技术
- 知识之间有层次递进关系,也有分门别类的整理
共包含 36 篇文章,分成五个模块详细介绍推荐系统的相关知识
- 概念篇:介绍一些推荐系统有关的理念、思考、形而上的内容,虽然务虚但是必要
- 原理篇:推荐算法的原理介绍,是俗称的干货。知道推荐系统背后技术的基本原理后,你可以更快地开发自己的系统,更好地优化自己的系统,并且更容易去学习专栏中未涉及的内容
- 工程篇:推荐算法的实践内容。系统落地时需要一些纯工程上的大小事情,架构、选型、案例等
- 产品篇:推荐系统要成功,还要考虑产品理念及其商业价值,因此这部分介绍一些产品知识和一点浅显的商业思考
- 团队篇:从个人来说,就是该怎么学习和成长;从团队来说,就是该招多少人,该有哪些人,以及产品经理和工程师该如何合作等问题
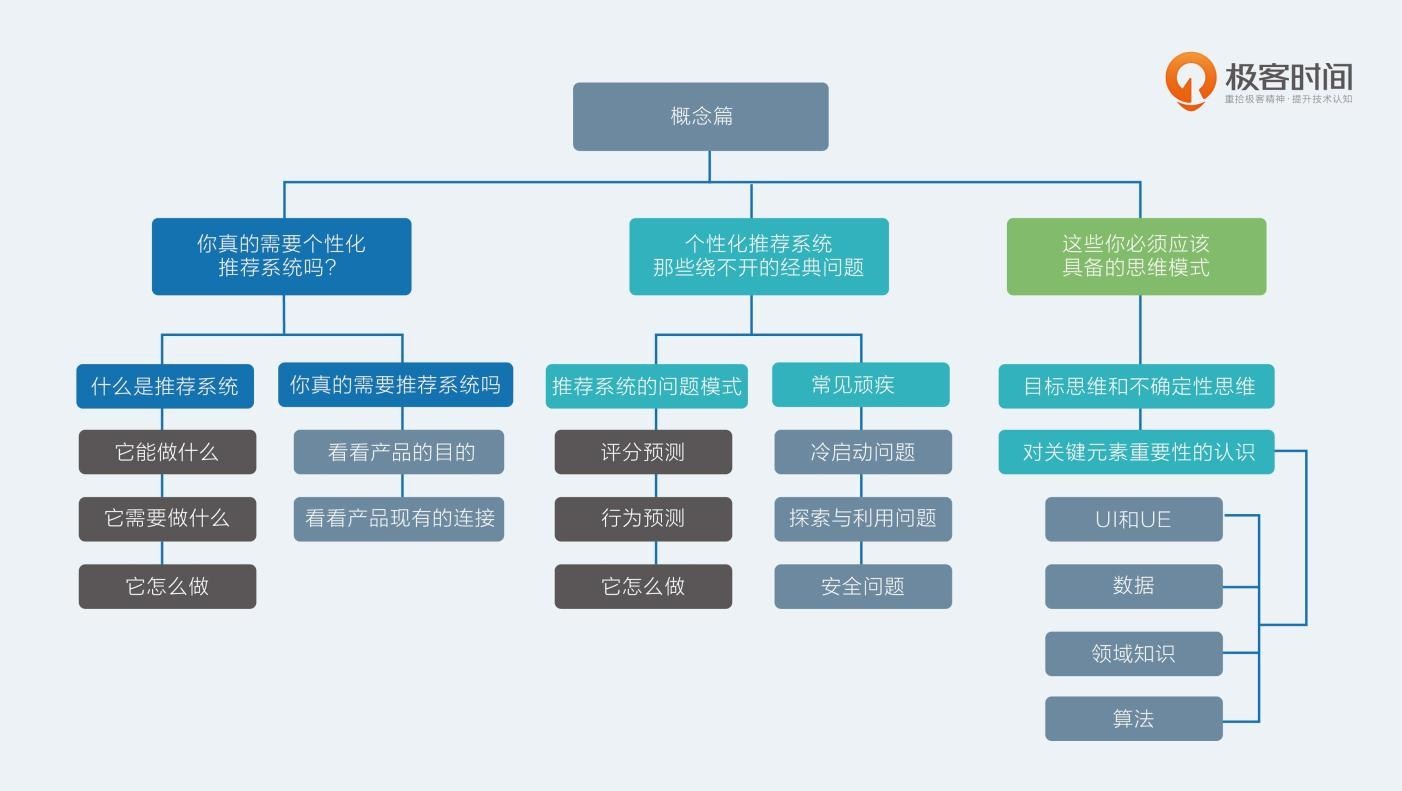
2.【概念篇】你真的需要个性化推荐系统吗?
什么是推荐系统?
按照维基百科的定义:它是一种信息过滤系统,手段是预测用户(User)对物品(Item)的评分和偏好。这个定义不是很好理解,也不恰当。它用“怎么做”来定义了“是什么”,这相当于变相规定了推荐系统的实现路径。
换一个角度回答三个问题来重新定义
- 它能做什么
- 它需要什么
- 它怎么做
对于第一个问题“它能做什么”,回答是:推荐系统可以把那些最终会在用户(User)和物品(Item)之间产生的连接提前找出来。
- 世界的发展趋势是万物倾向于建立越来越多的连接;
- 人是这一切趋势的意义所在,为人建立连接是要义;
- 根据已有的连接预测和人有关的连接,就是推荐系统。
对应的几个例子
- 一个社交产品,比如Facebook,如果它的20亿活跃用户之间已经都有社交关系了,那么它的“感兴趣的人”这一推荐系统就该寿终正寝了。从已经建立社交关系的用户身上去推测你还可能对哪些人感兴趣,本质上就是提前把那些可能的用户连接找出来,然后再按照用户分别呈现在每一个人面前。
- 一个信息流资讯阅读产品,比如今日头条,只有当用户不断点进源源不断的内容物品中,每一次点击,就是一个连接,每一次阅读也是一个连接,不同层次不同重要性的连接在推荐系统的帮助下不断建立,所主要依据的就是那些已经存在的连接,即:用户过去都点击阅读了哪些内容。
- 一个电商平台,用户刚买过什么,常买什么,你正在浏览什么,这些都是用户和物品之间已经存在的连接,用这些连接去预测还会买什么,还会看什么也是推荐系统。
回答第二个问题“它需要什么”:推荐系统需要已经存在的连接,从已有的连接去预测未来的连接。
对于第三个问题:怎么做?维基百科的定义提供了一个说法:预测用户评分和偏好。这是推荐系统背后相关算法和技术的两大分类,在后面的专栏内容中我会讲到;但比这个定义更抽象的实现方式分类是:机器推荐和人工推荐,也就是通常说的“个性化推荐”和“编辑推荐”。
总结一下推荐系统就是:用已有的连接去预测未来用户和物品之间会出现的连接。那么,你需要推荐系统吗?
已经根据“能做什么”“需要什么”“怎么做”三个方面,讨论了什么是推荐系统。那么只要前两个条件成熟,你就需要一个推荐系统,至于“怎么做”的问题则简单得多,否则的话就是暂时不需要。那么,如何判断条件是否成熟了呢?我们可以考虑两点。
第一,看看产品的目的。如果一款产品的目的是建立越多连接越好,那么它最终需要一个推荐系统。有哪些产品的目的不是建立连接呢?一种典型的产品就是工具类,如果是单纯提高人类某些工作的效率而存在的产品,比如一个视频编辑器,则不需要。虽然如今很多产品都从工具切入最后做成社区了,至少在工具属性很强时不需要推荐系统。
第二,看看产品现有的连接。如果你的产品中物品很少,少到用人工就可以应付过来,那么用户产生的连接肯定不多,因为连接数量的瓶颈在于物品的数量,这时候不适合搭建推荐系统。
长尾理论可以帮助我们理解,如何把用户和物品各种可能的连接汇总,包括用户属性、物品属性等,应该要有长尾效应才可能让推荐系统发挥效果。这里我介绍一个简单指标,用于判断是不是需要推荐系统:
分子是增加的连接数,分母是增加的活跃用户数和增加的有效物品数:
如果增加的连接数主要靠增加的活跃用户数和增加的物品数贡献,则该值会较小,不适合加入推荐系统; 如果增加的连接数和新增活跃用户和物品关系不大,那说明连接数已经有自发生长的趋势了,适合加入推荐系统加速这一过程。不过,具体并没有判断标准,因产品而异。
3.【概念篇】个性化推荐系统那些绕不开的经典问题
推荐系统的预测问题模式,从达成的连接目标角度区分,有两大类:
- 评分预测;
- 行为预测。
评分预测
评分预测相关算法模型研究的兴盛,最大的助攻是 Netflix 举办的推荐算法大赛。Netflix 比赛的评判标准就是 RMSE ,即均方根误差:
这个公式中的t表示每一个样本,n表示总共的样本数,$\hat y_t$就是模型预测出的分数,是我们交的作业,$y_t$就是用户自己打的分数,是标准答案,然后一个样本一个样本地对答案,模型预测分数和用户自己打分相减,这就是我们预测的误差。
评分预测问题常见于各种点评类产品(如:书影音的点评),但评分类推荐存在以下问题:
- 数据不易收集,我刚才说过,用户给出评分意味着他已经完成了前面所有的漏斗环节;
- 数据质量不能保证,伪造评分数据门槛低,同时真实的评分数据又处在转化漏斗最后一环,门槛高;
- 评分的分布不稳定,整体评分在不同时期会差别很大,个人评分在不同时期标准不同,人和人之间的标准差别很大。
用户们给产品施舍的评分数据,我们又叫做显式反馈,意思是他们非常清晰明白地告诉了我们,他们对这个物品的态度;与之相对的还有隐式反馈,通常就是各类用户行为,也就是另一类推荐系统问题:行为预测。
行为预测
推荐系统预测行为方式有很多,常见的有两种:
- 直接预测行为本身发生的概率
- 预测物品的相对排序。
直接预测用户行为这一类技术,有一个更烂大街的名字,叫做CTR预估。这里的C原本是点击行为Click,但这个解决问题的模式可以引申到任何其他用户行为,如收藏、购买。CTR 意思就是Click Through Rate,即“点击率”。 把每一个推荐给用户的物品按照“会否点击”二分类,构建分类模型,预估其中一种分类的概率,就是 CTR 预估。
隐式反馈,归纳起来:
- 数据比显式反馈更加稠密。诚然,评分数据总体来说是很稀疏的,之前Netflix的百万美元挑战赛给出的数据稀疏度大概是 1.2%,毕竟评分数据是要消耗更多注意力的数据。
- 隐式反馈更代表用户的真实想法,比如你不是很赞成川普的观点,但还是想经常看到他的内容(以便吐槽他),这是显式反馈无法捕捉的。而人们在Quora上投出一些赞成票也许只是为了鼓励一下作者,或者表达一些作者的同情,甚至只是因为政治正确而投,实际上对内容很难说真正感兴趣。
- 隐式反馈常常和模型的目标函数关联更密切,也因此通常更容易在AB测试中和测试指标挂钩。这个好理解,比如 CTR 预估当然关注的是点击这个隐式反馈。
用户给出较高评分的先决条件是用户要有“评分”的行为,所以行为预测解决的是推荐系统的80%问题,评分预测解决的是最后那 20% 的问题.
几个常见顽疾:
- 冷启动问题;
- 探索与利用问题;
- 安全问题。
冷启动问题
本身有伪命题的嫌疑,通常的解决方式就是给它加热:想办法引入数据,想办法从已有数据中主动学习(一种半监督学习)。
探索与利用问题
行话又叫做 EE (Exploit 和 Explore) 问题,一般有三种对待方式:
- 全部给他推荐他目前肯定感兴趣的物品;
- 无视他的兴趣,按照其他逻辑给他推荐,如编辑推荐、随机推荐、按时间先后推荐等等;
- 大部分给他推荐感兴趣的,小部分去试探新的兴趣,如同一边收割长好的韭菜,一边播种新的韭菜。
安全问题
推荐系统被攻击的影响大致有以下几个:
- 给出不靠谱的推荐结果,影响用户体验并最终影响品牌形象;
- 收集了不靠谱的脏数据,这个影响会一直持续留存在产品中,很难完全消除;
- 损失了产品的商业利益,这个是直接的经济损失。
4.【概念篇】这些你必须应该具备的思维模式
推荐系统的四个关键元素:
- UI 和 UE;
- 数据;
- 领域知识;
- 算法。
从上到下的权重大致是 4-3-2-1。其中UI 和 UE ,即人机交互设计和用户体验设计。好的UI 和 UE 才能带来数据的快速积累。UI、UE、数据是一个产品的基石,不论其有没有推荐系统存在都是基石。领域知识,与之对应的是常识和通识,此时业务逻辑显得更为重要。而一种对算法的常见误会就是:短期高估,长期低估。当前面三个要素都达到后,算法的意义就是使得产品的得到一个质的升华。
目标思维和不确定性思维
传统的软件是一个信息流通管道,从信息生产端到信息消费端的通道,比如一款内容App,写内容的可以正常记录,读内容的可以流畅加载,无论多大的并发量都扛得住,这就是一个正常的产品了。但推荐系统这种产品,如果是一个产品的话,它和作为信息流通管道的本质不一样,它是一个信息过滤工具,要解决的问题不是信息流通本身,而是如何让流通更有效率。
核心词可以表述为:逻辑、因果、分层。通常来说,训练机器学习模型是一个不断小化(或者大化)目标函数的过程。我们把一个推荐系统也看做一个函数,这个函数的输入有很多:UI、UE、数据、领域知识、算法等等,输出则是我们关注的指标:留存率、新闻的阅读时间、电商的 GMV、视频的 VV 等等。目标思维背后是“量化一切”的价值取向。
- 确定性思维:它是完全依靠逻辑和因果链条引发而成的,只要初始条件给定,那么结果就是一定的
- 不确定性思维:不用因果逻辑严丝合缝地提前推演,而是用概率的眼光去看结果
例如:“为什么出现这个”和“出现这个的可能性有多大”
需要不确定性思维的原因:
- 绝大多数推荐算法都是概率算法,因此本身就无法保证得到确切结果,只是概率上得到好的效果;
- 推荐系统追求的是目标的增长,而不是一城一池的得失;
- 如果去花时间为了一个 Case 而增加补丁,那么付出的成本和得到的收益将大打折扣;
- 本身出现意外的推荐也是有益的,可以探索用户的新兴趣,这属于推荐系统的一个经典问题:EE 问题。