
1 RP
R(recall)表示召回率、查全率,指查询返回结果中相关文档占所有相关文档的比例;P(precision)表示准确率、精度,指查询返回结果中相关文档占所有查询结果文档的比例。假设有如下的混淆矩阵:
| —- | Predict P | Predict N |
|---|---|---|
| Target P | TP | FN |
| Target N | FP | TN |
正确率、召回率(查全率)、精准度、$F_{\beta}$ score、假阳率以及真阳率:
其中,F-Score/F-measure 作为综合指标,平衡 recall 和 precision 的影响,较为全面的评价一个模型。F1-Score 表示准确率和召回率一样重要;F2-Score 表示召回率比准确率重要一倍;F0.5-Score 表示准确率比召回率重要一倍。
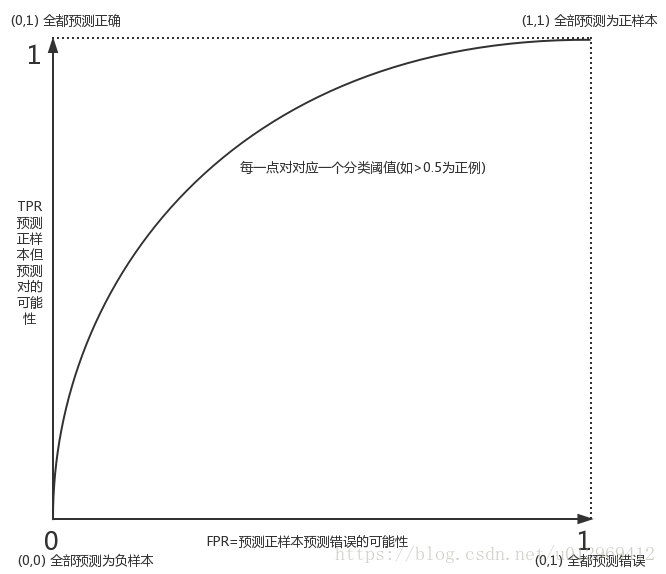
其中:
假阳率FPR=ROC曲线的X轴指标
真阳率TPR=ROC曲线的Y轴指标=召回率
AUC值就是曲线右下部分面积。
2 MAP
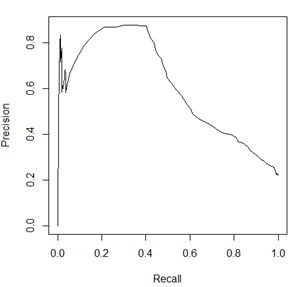
如上图的PR曲线,对其进行积分求曲线下方的面积,就是AP(Average Precision),即
其中,p 表示 precision,r 表示 recall,p 是一个以 r 为参数的函数,AP 的计算是对排序位置敏感的,相关文档排序的位置越靠前,检索出相关的文档越多,AP 值越大。
近似计算约等于 AAP(Aproximate Average Precision):
其中,N 代表所有相关文档的总数,p(k) 表示能检索出 k 个相关文档时的 precision 值,而 △r(k) 则表示检索相关文档个数从 k-1 变化到 k 时(通过调整阈值)recall 值的变化情况。
rel(k) 表示第 k 个文档是否相关,若相关则为1,否则为0,则可以简化公式为:
其中,N 表示相关文档总数,position(i) 表示第 i 个相关文档在检索结果列表中的位置。
MAP(Mean Average Precision)即多个查询的平均正确率(AP)的均值,从整体上反映模型的检索性能。
下面举一个例子来说明上述公式的计算:
查询 query1 对应总共有4个相关文档,查询 query2 对应总共有5个相关文档。当通过模型执行查询1、2时,分别检索出4个相关文档(Rank=1、2、4、7)和3个相关文档(Rank=1、3、5)。
则 query1AP=(1/1+2/2+3/4+4/7)/4=0.83,query2AP=(1/1+2/3+3/5+0+0)/5=0.45,最后 MAP=(0.83+0.45)/2=0.64。
3 NDCG
3.1 CG(Cumulative Gain)累计效益
其中 k 表示 k 个文档组成的集合,rel 表示第 i 个文档的相关度,例如相关度分为以下几个等级:
| Relevance Rating | Value |
|---|---|
| Perfect | 5 |
| Excellent | 4 |
| Good | 3 |
| Fair | 2 |
| Simple | 1 |
| Bad | 0 |
3.2 DCG(Discounted Cumulative Gain)
在 CG 的计算中没有考虑到位置信息,例如检索到三个文档的相关度依次为(3,-1,1)和(-1,1,3),根据 CG 的计算公式得出的排名是相同的,但是显然前者的排序好一些。
所以需要在 CG 计算的基础上加入位置信息的计算,现假设根据位置的递增,对应的价值递减,为 1/log2(i+1),其中 log2(i+1) 为折扣因子;
另一种增加相关度影响比重的 DCG 计算公式:
3.3 IDCG(idea DCG)
理想情况下,按照相关度从大到小排序,然后计算 DCG 可以取得最大值情况。
其中 |REL| 表示文档按照相关度从大到小排序,取前 k 个文档组成的集合。就是按理想排序情景的前k个。
3.4 NDCG(Normalized DCG)
由于每个查询所能检索到的结果文档集合长度不一致,k 值的不同会影响 DCG 的计算结果。所以不能简单的对不同查询的 DCG 结果进行平均,需要先归一化处理。
NDCG 就是利用 IDCG 进行归一化处理,表示当前的 DCG 与理想情况下的 IDCG 相差多大:
这样每个查询的 NDCG 均在 0-1 范围内,不同查询之间就可以进行比较,求取多个查询的平均 NDCG。
4 ERR
4.1 PR(reciprocal rank)
倒数排名,指检索结果中第一个相关文档的排名的倒数。
4.2 MRR(mean reciprocal rank)
多个查询的倒数排名的均值,公式如下:
ranki 表示第 i 个查询的第一个相关文档的排名。
4.3 Cascade Model(瀑布模型)
点击模型中的瀑布模型,考虑到在同一个检索结果列表中各文档之间的位置依赖关系,假设用户从上至下查看,如果遇到某一检索结果项满意并进行点击,则操作结束;否则跳过该项继续往后查看。第 i 个位置的文档项被点击的概率为:
其中 ri 表示第 i 个文档被点击的概率,前 i-1 个文档则没有被点击,概率均为 1-rj;
4.4 ERR(Expected reciprocal rank)
预期的倒数排名,表示用户的需求被满足时停止的位置的倒数的期望,与 RR 计算第一个相关文档的位置倒数不同。
首先用户在位置 r 处停止的概率 PPr 计算公式如下:
其中 Ri 是关于文档相关度等级的函数,现假设该函数为:
当文档是不相关的(g=0),则用户检索到相关文档的概率为0;而当文档极其相关(g=4,如果相关度划分5个等级)时,用户检索到相关文档的概率接近于1。上面公式中的 g 表示文档的相关度,参考 NDCG 中的 rel。
更通用一点来讲,ERR 不一定是计算用户需求满足时停止的位置的倒数的期望,它可以是基于位置的函数
可以看出,当 φ(r)=1/r 时就是 ERR,当 φ(r)=1/log2(r+1) 就是DCG。
参考文章:https://www.cnblogs.com/memento/p/8673309.html