
1 引言
在推荐系统中一个重要的任务就是 CTR 建模,其本质的思想便是预估 user 对 item 的点击率。但是实际中获取的样本往往是在一定条件(时间、机型、位置等)下的后验结果,所以使得建模的 Label 往往是夹杂了这些因素的结果。
这些影响后验结果的因素一般称为 偏置(bias)项,而去除这些偏置项的过程就称为 消偏(debias)。在这其中最重要的便是 位置偏置(position bias),即 item 展示在不同位置会有不同的影响,且用户往往更偏向点击靠前的位置。本文将重点介绍业界在 position bias 消除上的一般做法和相关经验。
2 Position Bias
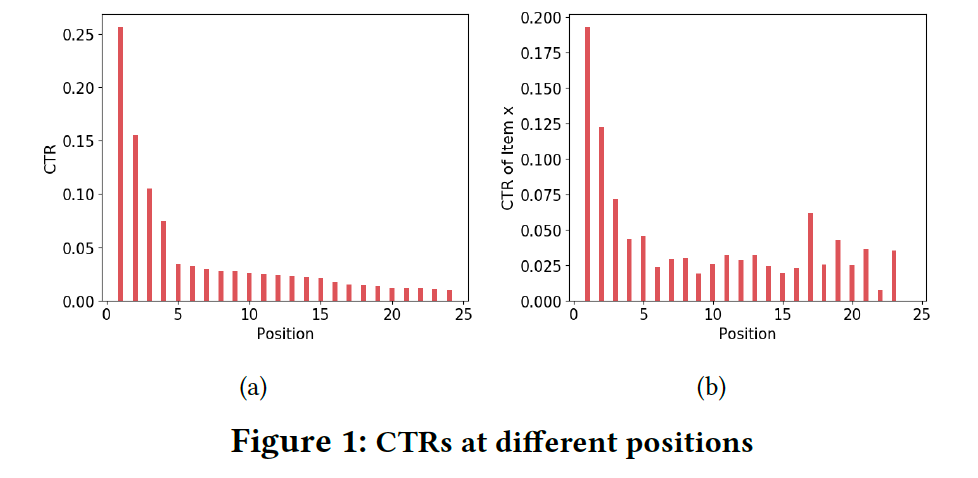
看下面的图,是笔者实际工作场景中部分位置的 CTR 趋势图。可以明显地看到:
- 呈现每 20 个 position 位一个周期;每刷请求的个数是 20.
- 周期内位置越靠前,CTR 越大;靠前效率高,用户更偏好点靠前的。

在华为的研究中也论证了用户对 position 靠前的偏好。固定 item 在不同 position 的 CTR 和不固定 item 的趋势差别较为显著。
3 Position Debias—特征法
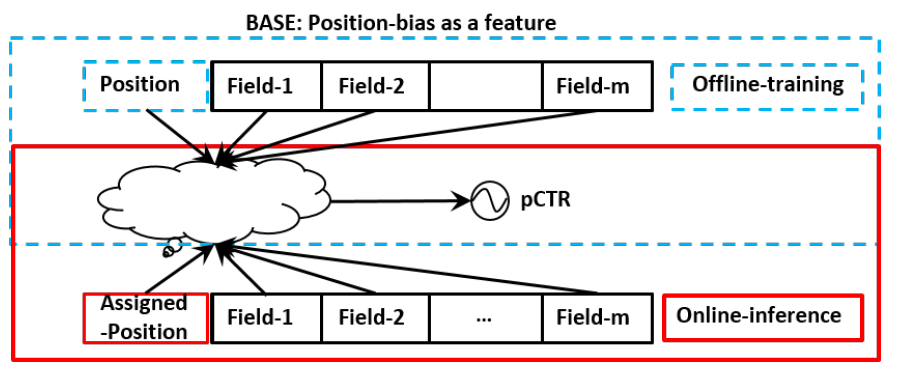
比较朴素的想法,便是在特征体系中引入 position, 如上图所示。
- 模型
offline training的时候,把 position 作为特征输入模型,让模型学习 position 带来的后验影响。 - 而在
online infer的时候,并没有 position 这样后验的信息,往往可以选择填充一个默认值,比如 0。
注意:具体填什么也需要测试,不同默认值的结果差别还不小。
4 Position Debias—Shallow Tower
此方法核心是:构建一个 Shallow Tower 来预估 Position Debias。
方法来源是 Youtube 发表在 RecSys 2019上的文章:Recommending What Video to Watch Next: A Multitask Ranking System
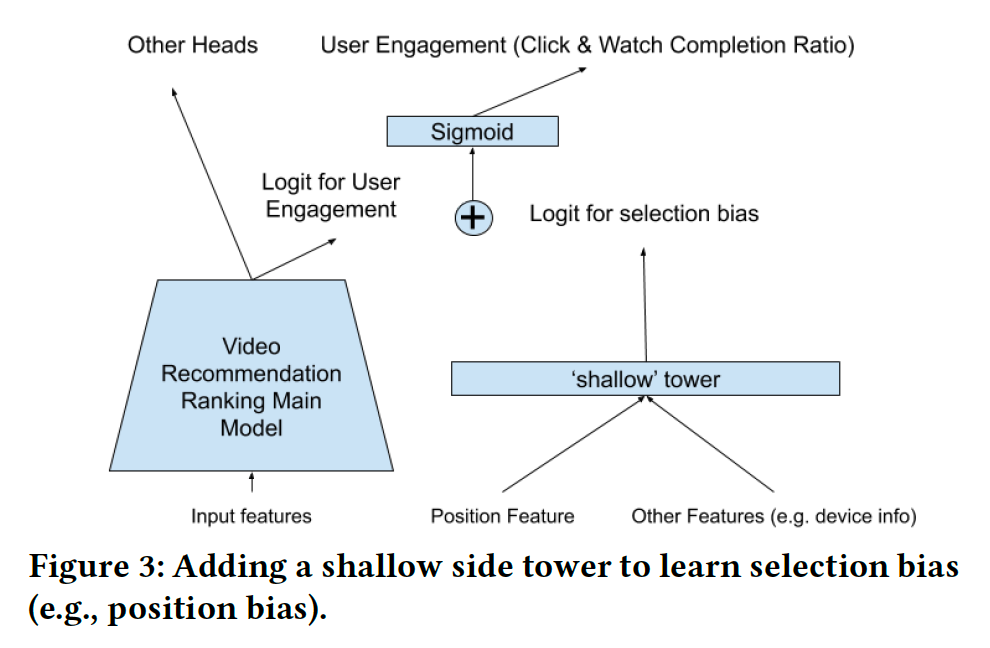
如上图所示,文章阐述在 position debias 上的做法是:
- 保持原来的主模型(main model)不变
- 新增一个专门拟合 position bias 的浅层网络(shallow tower)
- 将 main model 和 shallow tower 的 logit 相加再过 sigmoid 层后构建 loss。
其中,shallow tower 的输入主要包含 position feature, device info 等会带来 bias 的特征,而加入 device info 的原因是在不同的设备上会观察到不同的位置偏差。
注意:文章提到在 training 的时候,position 的特征会应用 10% 的 drop-out,目的是为了防止模型过度依赖 position 特征。在 online infer 的时候,由于没有后验的 position 特征,直接丢掉 shallow tower 即可。
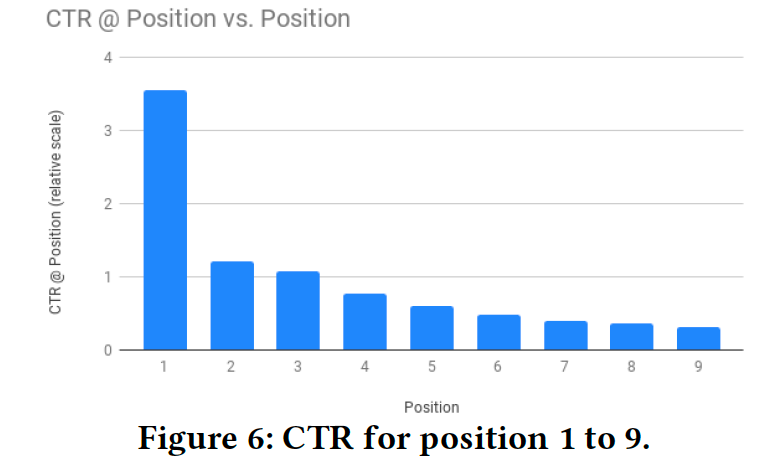
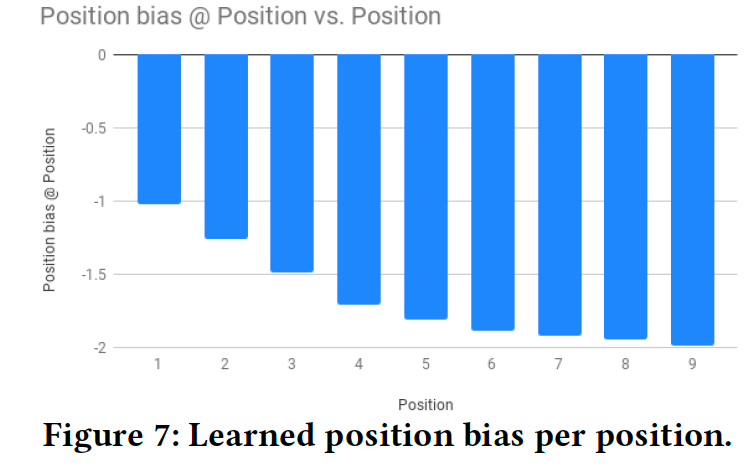
在文章中,披露了模型训练结果提取出的 position bias,如下图所示,可以看到随之位置的增长,bias 越大。因为越靠后,用户更有可能看不到。
实际上,bias 还可以拓展更多的特征,包括 user 和 item 侧的属性,具体如何还需依赖对业务的理解和实验。
5 Position Debias—PAL
此方法核心是:将 position bias 从后验点击概率中拆出来,看作是用户看到的概率。
方法来源是华为发表在 RecSys 2019上的文章:PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems
如上公式,作者将后验点击概率拆成了2个条件概率的乘积:
- Item 被用户看到的概率
- 用户看到 item 后,再点击的概率
那么可以进一步假设:
- 用户是否看到 item 只跟位置有关系
- 用户看到 item 后,是否点击 item 与位置无关
基于上述假设,就可以建模如下:
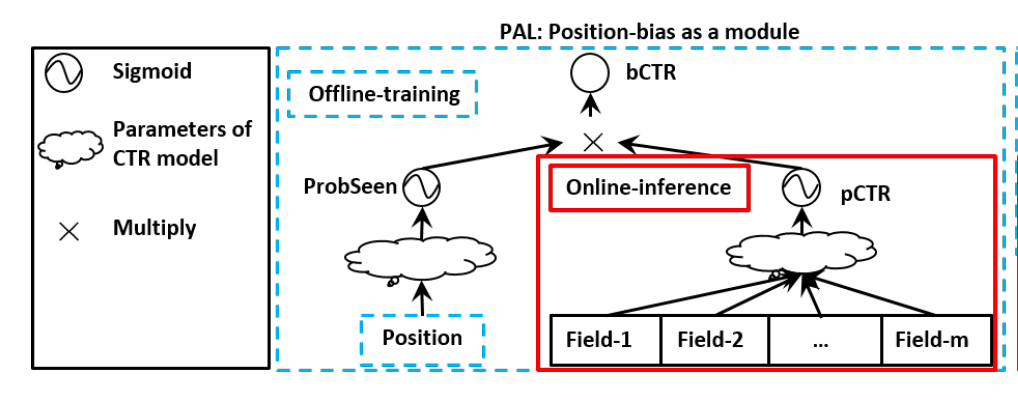
如上图所示,其中:
ProbSeen: 是预估广告被用户看到的概率pCTR:是用户看到 item 后,点击的概率
可以看到与 YouTube 做法的区别主要有2点:bias net 和 main model 都先过激活层;然后两边的值再相乘。
最后 loss 是两者的结合:
在 online infer 的时候,也是类似地丢掉 position 相关的 ProbSeen 的网络,只保留 pCTR 部分即可。
6 拓展思考
6.1 假设是否成立?
两种主流的做法都是将 position 等可能造成 bias 影响的信息单独构建 bias net,然后与 main model 进行融合。
但是,
Position 带来的 bias 是否可以独立于 main model 进行建模?
用户是否看到是否可以简化为只与 position 相关?
Bias net 的作用是否可以简化为与主塔结果的相加再激活/先激活再乘积?
上述问题也许没有标准答案。实际上,笔者在实际中还做了另一种方案,即真的只将结果看成 bias 项,那么就简单的与主网络相加即可,实际上结果也不差。为了控制值域依然在 (0,1) 从而不影响 loss 的构建,最终输出变成:
6.2 pCTR 的分布问题
容易发现,无论哪种 bias net 的融合方式,最后 loss 所使用的 pCTR 已经发生了变化,而在 online 阶段去除 bias net 部分后,保留的 main tower 对应的输出 pCTR 的分布必然会发生变化。最明显的表现就是 pcoc(sum(clk)/sum(pCTR)将会偏离 1 附近。
而这带来的影响就是:
如果后排和重排中使用到 pCTR 的时候,就会出现含义偏离,会带来一些连锁效应,并且不利于数据分析。当然,有的系统可能没有这个要求。
对于这个问题,笔者试过一些缓解方案:
- 增加辅助 loss:比如主网络的 pCTR 也增加一个 logloss 来修正齐 pcoc
- 增加 pcoc 正则:针对主网络的 pCTR 新增一个 pcoc 偏离 1 的惩罚项,类似于正则的思想
- 矫正结果分值:统计主网络输出偏离期望的比例,直接将输出结果根据该值进行矫正即可
从效果上来说:
- 辅助 loss 和正则的方式确实有助于改善 pcoc,但往往也会影响效果,毕竟梯度被分散了;
- 矫正的方式最明显,但是会面临校正系数变化的问题。
6.3 业务效果
在推荐系统中,一切脱离实验业务效果的优化,往往都不够坚挺。笔者主要在电商推荐领域内,那么这里给出的经验也仅仅针对此类做参考,不一定具有普适性。
笔者主要实验了 PAL 和 $\frac{1}{2}(p(seen|pos) + p(y = 1|x, seen))$ 的方式,并且都做了预估分值矫正。离线上 auc 往往会有微幅提升。线上的 CTR 和 IPV 一般会有一定涨幅,在笔者的实验中 +1% 左右。
但是,一些体验指标变差了,比如负反馈率、猎奇品的占比等。综合分析下来,click 主要涨在猎奇、标题党等低质品的流量增加上,是不利于系统健康的,于是最终实验没有推全。当然,如果是 UGC 或者 Ads 类业务可能会是另一个逻辑,所以仅供参考。
参考文章
推荐生态中的bias和debias
SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案
推荐系统中的bias&&debias(二):position bias的消偏
Recommending What Video to Watch Next: A Multitask Ranking System
PAL: a position-bias aware learning framework for CTR prediction in live recommender systems
Bias and Debias in Recommender System: A Survey and Future Directions