
1 背景
这是一篇推荐算法领域经典的论文,它由 YouTube 在2016年发表在 RecSys 上的文章Deep Neural Networks for YouTube Recommendations。
这篇文章是诸多推荐算法工程师的必学经典,可能很多人多次重读都会有新的思考,本文也重点总结文章的核心内容与一些实战经验的思考。
2 原理
首先便是其展示的系统链路示意图,这块与大多主流方案没有什么区别。
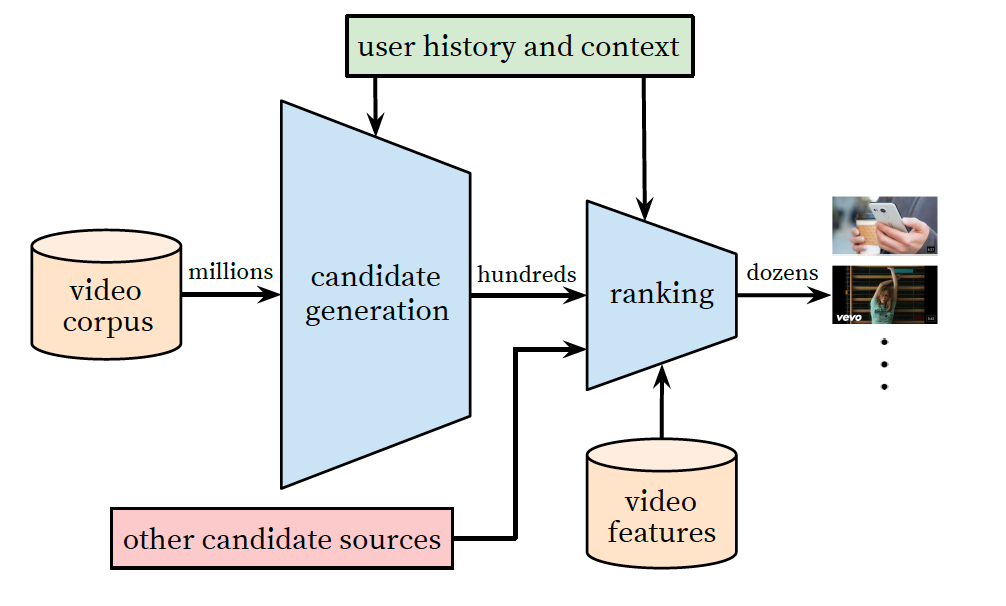
论文分别介绍了在 recall 和 ranking 两个模块的方案,但可以说,recall 部分的重要性远大于 ranking。就此文章发表后的几年而言,recall 往往还在工业界主流召回的候选方案中,但 ranking 的方案基本已经成为历史,很少再使用了,不过其思想还是值得学习的。
2.1 recall
任务目标:预测用户下一个观看的视频(next watch),一个多分类问题。
这里先上模型结构,如下图所示。
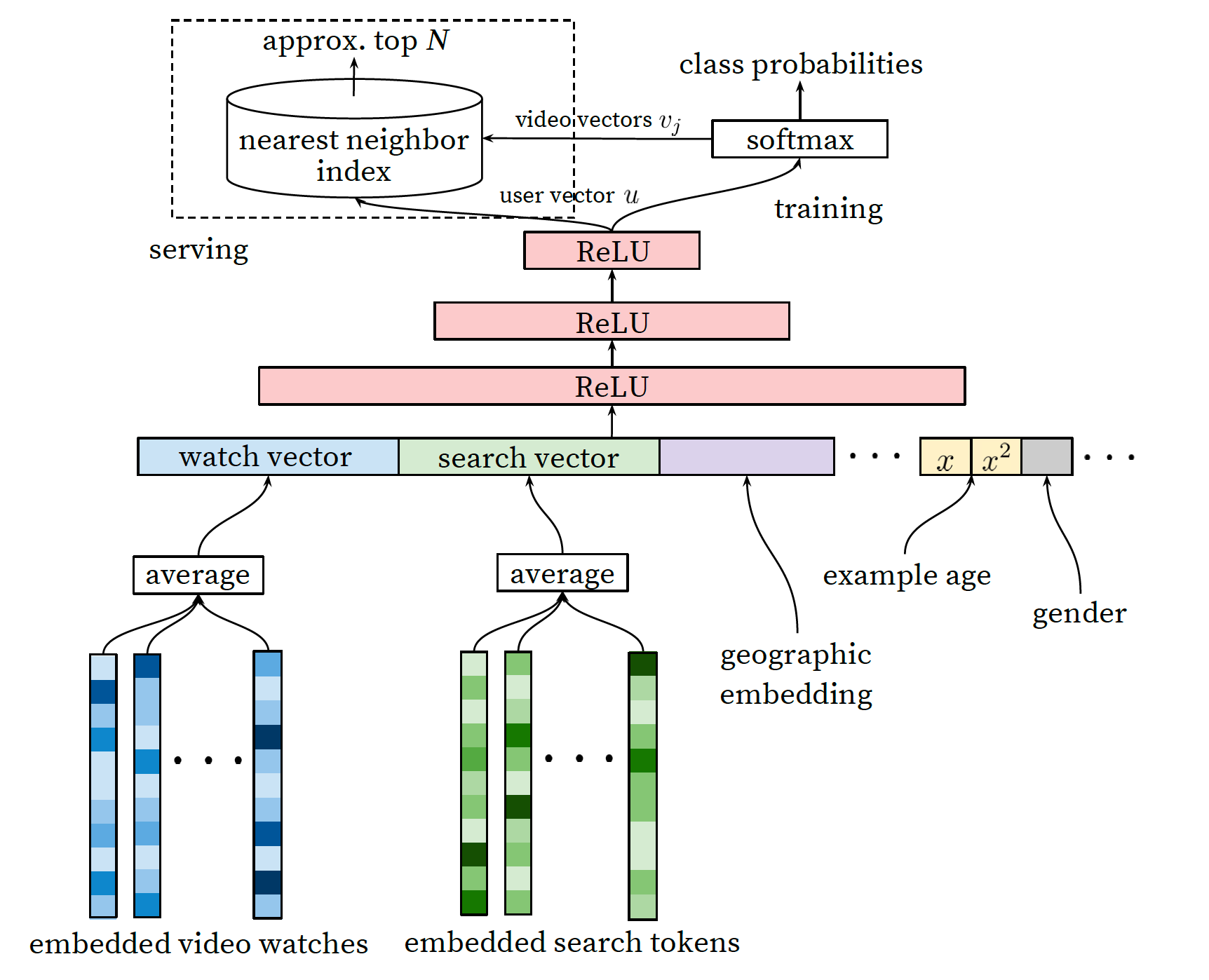
特征
- 用户历史看的视频序列,取 embedding 做
average pooling; - 用户历史搜索的 token 序列,也做
average pooling; - 用户的地理位置、性别、年龄等;
- 样本年龄(后续单独介绍)。
之后便是把所有 embedding 进行 concat 拼接,过3层 DNN 以得到 user vector 即 user embedding。
注意:这里只有 user 的特征输入。
这是召回模型的通用方法,类似于双塔模型。主要是先构建 user embedding 的网络,利于后续线上服务。而与 item 的交互,往往放在最后一个环节。
可以看到,在 user vector 生成后,被分成了 training 和 serving 两个分支。
先看 training 部分,看上去2步:
- 先经过 softmax 层预估 video 的多分类概率;
- 然后产出 video vector 供 serving 使用。
我们假设 3 层的 DNN 后得到的 user vector 是 K 维的,而需要进行多分类的候选集有 M 个 video,那么 training 侧的结构便是:
如果 $user_{vec}$ 是 $1 \times K$ 的,那么 $W$ 便是 $K \times M$ 的,如此输出就是 M 维的 softmax 结果。那么 W 的 M 列 K 维向量即可作为候选集 M 个 video 的 vector。
其实不用陌生:让我们再次联想召回的双塔模型,是不是就相当于将候选 M 个 video 先过 embedding 层,之后与user vector 做点积,这也是召回模型的经典做法。
再看 serving 环节,也是经典的召回方案。即:
- 离线模型中训练好的 video vector 保存下来;
- 将 video vector 构建到 ANN 等向量索引库中;
- 线上 serving 的时候,user vector 通过模型实时 infer 得到;
- 用 user vector 和索引库进行近邻召回。
如此的优势:
- 因为每次 serving 需要处理的 video 很多,其 vector 不适合实时生成;
- 每次 serving 时 user vector 只需要 infer 一条样本,性能可控,捕捉 user 实时偏好就更重要。
样本年龄
针对论文提到的 Example Age 特征,可能很多人(包括我本人),一开始对此理解是;
视频上架距离 log 的时间差,比如曝光的视频已经上架 48h,那么该特征便是 48。即文中的
Days Since Upload。
然而,结合其他观点和重读论文,应该是:
sample log距离当前的时间作为example age,比如一条曝光/点击日志 ,发生在 2h 前,在被 training 的时候,也许其 video 已经上架 48h 了,但 example age 特征的取值是前者 2。
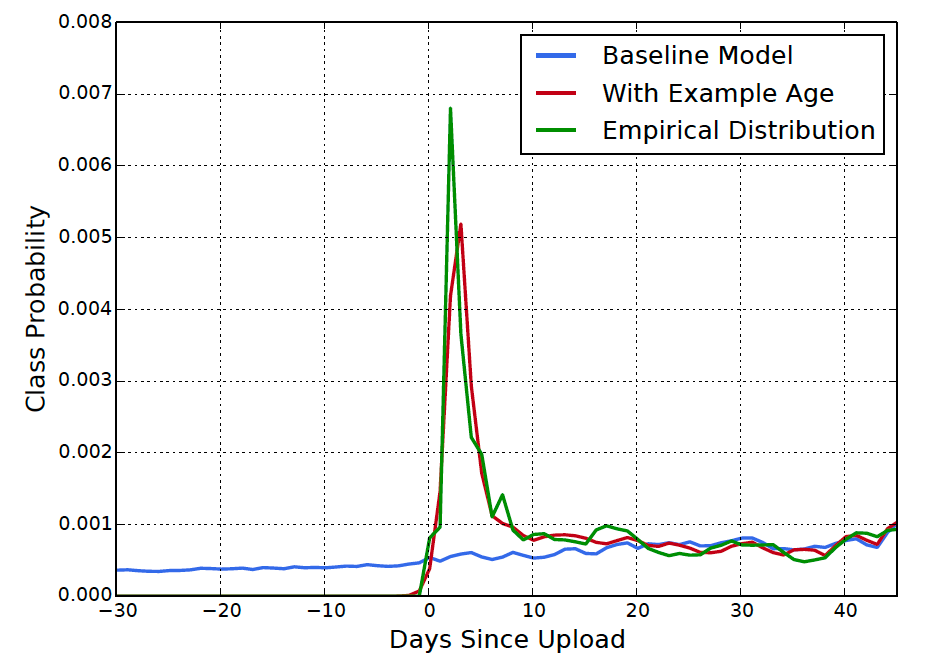
作者提到,在加入该特征后,模型能够较好地学习到视频的 freshness 程度对 popularity 的影响。体现在下图的 Days Since Upload 后验分布的变化,新模型比 baseline 表现得更接近真实分布。
2.2 ranking
优化目标:expected watch time,即视频期望观看时长。
这里我们重点介绍一些核心,先上模型结构图:
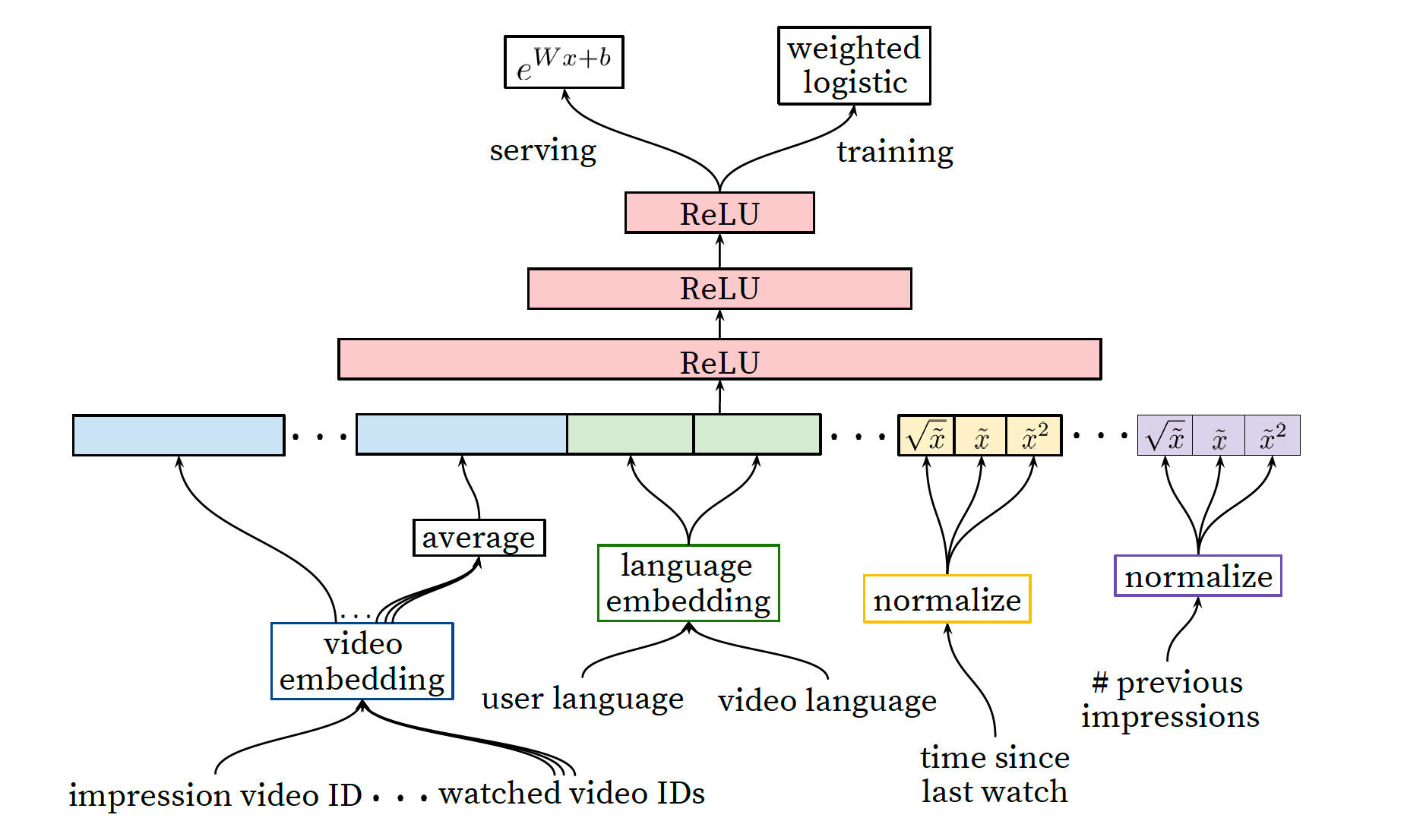
特征:
video embedding:impression video ID: 当前待评估的video的embeddingwatched video IDs: 用户最近观看的N个 video 的 embedding 的 average pooling
language embedding:user language: 用户语言的 embeddingvideo language: 当前视频语言的 embedding
time since last watch: 用户上次观看同 channel 视频距今的时间#previous impressions: 该 video 已经被曝光给该用户的次数
披露的特征设计非常经典且贴合实际业务,也许真实的特征体系比这要更丰富,但论文披露的更多是特征设计的思想。
video embedding代表了捕捉用户历史行为序列关于当前视频的相关度;language非常具有 youtube 全球视频网站的特色,捕捉用户与视频语言差异。- 后面的2个统计值度量了一些时间因素,用户看同
channel隔了多久以捕捉兴趣衰减,已经曝光的次数代表了用户忽视程度。
此外,论文提到了一些trick:
- 连续型特征做
normalization,利于模型收敛; - 部分统计特征进行了
box-cox 变化,是一种增加特征非线性输入的办法,辅助模型训练; - 长尾 video,其 embedding 用 0 来代替,降低长尾影响。
模型将输入 embedding 进行 concat 后过了一个 3 层 DNN,之后类似 recall 环节,又分成了 training 和 serving 这2个分支,实际上这里是巧妙地将回归问题转分类了。
training时,Weighted LR 方式,label 为是否观看,weight 是观看时长,作用在 loss 上;serving时,使用 $e^{wx+b}$ 作为观看时长的预估值,其中指数部分是训练时 sigmoid 的 input 部分。
3 实践经验
结合王哲老师的工程10问,这里总结和补充一下个人认为比较重要的实战经验,供自己复盘和其他读者批评。
3.1 Recall model 的性能问题
next watch 的目标下,候选 video 有数百万量级,这在使用 softmax 进行多分类更低效。论文有提到这块,类似于 word2vec 的解决方案,负采样(negative sampling)或者 分层处理(hierarchical softmax)。效果是没有太大差异,一般负采样使用更广泛。
其原理是:每次不用预估所有候选,而只采样一定数量(超参数)的样本作为负样本,甚至进一步可以转化成基于点积的二分类。
3.2 Ranking Model 为什么选择用分类而不是回归?
我认为在该问题上主要有2点。
- 是业务目标的决策。如果是点击等目标天然满足,这里这不满足此。
- 实际工业应用中,以时长等连续型数据作为 Label 时,因其具有严重的长尾分布特性,这会使得回归模型在拟合过程中容易欠佳。一般体现在对 Label 值过低和过高的两端样本拟合偏差,MSE、PCOC等预估统计量偏差很大。因而一般会转成分类任务来处理。
具体原因则和回归模型特性以及样本梯度分布有关系,不过多赘述。相对地,分类模型则在这方面稳健性会高一些。
3.3 Ranking model 使用 weighted LR 的原理
我们来理解一下为什么论文中做法能生效?这里阐述一下个人的理解。
其中 z 是最后一层,即 $z = wx+b$。
那么 LR 模型的交叉熵 loss 为:
那么,如果我们将 label 由“是否观看”变成 $\frac{t}{1+t}$ ,其中 t 是观看时长,那么 loss 就变成:
注意!这时候,$p$ 拟合的就是 $\frac{t}{1+t}$,当其不断逼近的时候,就有:
故,在 serving 的时候就使用 $e^{z}=e^{wx+b}$作为观看时长 t 的预估值。
进一步,因大多时候 1+t 等于或接近1,那么 loss 近似等价于:
注:这里类似王哲老师提到的“概率p往往是一个很小的值”来近似上一个道理。
这便是一个目标是否观看的 weighted LR 的 loss,且 weight 为观看时间 t。
补充:Weighted LR 实际上就是 WCE(weighted cross entropy) Loss,一般来说有两种方法:
- 将正样本按照 weight 做重复 sampling;
- 通过改变梯度的 weight 来得到 Weighted LR (论文方法)。
但是 WCE 有2个缺点:
- 其实假设了样本分布服从几何分布,否则可能导致效果不好;
- 在低估时($\hat y < y$)梯度很大,高估时($\hat y > y$)梯度很小,很容易导致模型高估。
3.4 如何生成 user 和 video 的 embedding?
文中介绍用 word2vec 预训练得到。当然,我们知道,也可以使用 embedding layer 去联合训练,且往往这种实践更好,也是现如今的主流做法。
3.5 example age 的处理和原因?
猜想:可能是从特征维度区分开历史样本的重要度,越新的样本(不是 video)可能对模型参考价值越大。有点类似于 biasnet 的修正作用。
比如有一个 video(不一定新上架) 1h 前有很多正样本,且越来越少,那么模型通过此特征可能能够感知到这种热度的时序变化趋势。
但,对于 youtube 而言,其模型训练应该是:
- 实时(至少日内)的;
- 批次增量的(即不会回溯更久远的样本);
假设样本的切分窗口为 T(比如2h),那么就一定 $0<example age<T$,那么问题来了:
样本只能学习到该特征在(0,T)的分布,但论文图中却展示 Days Since Upload 特征的后验分布改善了。
serving 的时候,虽然说通过置0来消除 example age 的bias,但实际上样本距离当下的时间又发生了变化,即 example age 信息发生了偏移。
总结:也许这两个特征都在模型中,且交叉效应大于边际效应。描述 video fresh 程度交给 Days Since Upload 特征,再加上描述 sample fresh 程度的 example age。能够使得前者后验预估的更准确,也能够通过后者修正历史样本的 times bias。
3.6 为什么对每个用户提取等数量的训练样本?
原文中提到“这是为了减少高度活跃用户对于loss的过度影响。”但实际上个人觉得这个方法可能不一定最适合。结合逻辑和个人经验,个人认为主要有2点:
- 模型学习了一个有偏于真实分布的样本,预估会有偏差;
- 本末倒置,使得低活的影响力反而增强,线上 ABtest 的时候,其贡献往往不足,因线上业务收益往往也是高活主导,二八法则;
虽如此,倒不是说高活不应该抑制,对于比较异常的高活,可以针对他们样本欠采样或者加正则,而不是只有通过提高重要性更低的非高活人群的作用。
3.7 为什么不采取类似RNN的Sequence model?
论文提到主要是过于依赖临近行为,使得推荐结果容易大范围趋同于最近看过的 video。
此外,还有一个比较重要的原因便是 serving 时候的 infer 性能问题。
3.8 为什么长尾的video直接用0向量代替?
把大量长尾的video截断掉,主要是为了节省online serving中宝贵的内存资源。
但现在问问不会这么粗暴的使用,一般是将长尾物料进行聚类,以改善他们样本过于稀疏而带来的收敛困难问题。极端情况就是聚为1类,共享一个 embedding,类似于冷启动一样,当逐渐脱离长尾后再出场拥有独立的 embedding。
参考文章
Deep Neural Networks for YouTube Recommendations
Weighted LR (WCE Weighted cross entropy)
推荐系统(二十)谷歌YouTubeDNN
重读Youtube深度学习推荐系统论文
YouTube深度学习推荐系统的十大工程问题
排序04:视频播放建模