
1 引言
本文先假定读者对推荐系统有一定了解,尤其是召回、精排和重排3个部分,如此阅读本文可能更顺畅。
LTR(Learning to Rank)即排序学习,在当下的搜广推业务中应用广泛,思路上主要分为四类:
- 基于
Point-wise。主要考虑 user、item、以及 context 信息特征,仅关注当前 item 自身的效率,比如Wide & Deep、ESSM等。 - 基于
Pair-wise。训练时通过损失函数来预估item pair之间的相对位置关系,高 Label 排在低 Label 前则为正例,否则,为反例。模型的目标是减少错误 item pair 的个数,不考虑列表信息,模型训练复杂度问我较高,比较典型的如RankNet。 - 基于
List-wise。训练时候对每个request下的整个item list构建 Loss,拟合最优序列分布。比较典型如LambdaMART、DLCM、以及ListMLE等。 - 基于
Generator-evaluator。一般分为 2 模块,序列的召回和排序。重排召回即按照一定排序算法,生成一系列预期reward较高的候选 List,再针对这些上下关系已经固定的 List 进行整页建模预估reward,选择top1 list输出。
本文将重点聚焦在第 4 种,即基于 Generative-evaluate 的 LTR 模型,因为此类做法有两个特点:
- 可真正实现对 List 进行整页建模的;
- 可在重排环节实践落地的。
虽然第 3 种一般也称为 List-wise,但实际上更多的是对精排模型训练的 Loss 进行优化,最终 infer 的时候依然是 Point-wise。当然,它也是有一定效果,不过不是本文想讨论的重点。本文主要基于 Generative-evaluate 来讨论对整个 List 的建模和预估,并总结部分笔者的实践经验。
2 模型原理
2.1 场景
重排的环节,往往是基于用户 U 和上下文 C,需要从上游(一般是精排)给到候选物品集合 I 中选出 K 个并组成有序 List 展示给前端用户。
故,重点就在如何挑选并排序成最优列表 O,以达到业务目标上的最大化,比如点击、下拉曝光、订单转化等。一般传统做法都是基于精排多目标预估融合分,使用 MMR/DPP 等重排算法,再结合业务规则,进行重排。
精排缺陷:
- 精排
pointwise建模缺少空间信息的考虑,即当前 item 的上下内容(一般该假设都成立); - 基于精排分+规则的贪心重排方案往往与全局最优偏差较远;
MMR,DPP重排也是在目标中给予多样性一些权重,各有优劣。
重排目标:
- 需要考虑序列空间信息,例如序列窗口特征、或
transformer结构; - 建模优化目标要做到 List 整体,而不是 Pointwise 式;
- 框架能够具备不断发掘更优序列的能力,防止系统模型退化。
2.2 方案思路
一个排序结果的好坏,需要 List 固定后,才能结合整个空间排布和上下文信息来真正得进行 Listwise 评估。
基于上述讨论,我们将重排分为了两个阶段:
重排-召回:使用 MMR 等不同算法,朝着业务目标生成多样的候选序列作为序列召回集;重排-排序:构建序列评估模型,对候选序列集进行真正的 Listwise 评估,选出最优序列。
如下图所示,右侧上半部分单点重排便是一个典型的传统重排方案。相对应的,下半部分是结合了序列检索和序列评估的重排模块。
我们将从候选集合中选择不同的物品排列成不同的序列视作推荐系统的召回,再从这些序列中选出最好的就可以作为推荐系统中的排序,之后便可以直接输出了。
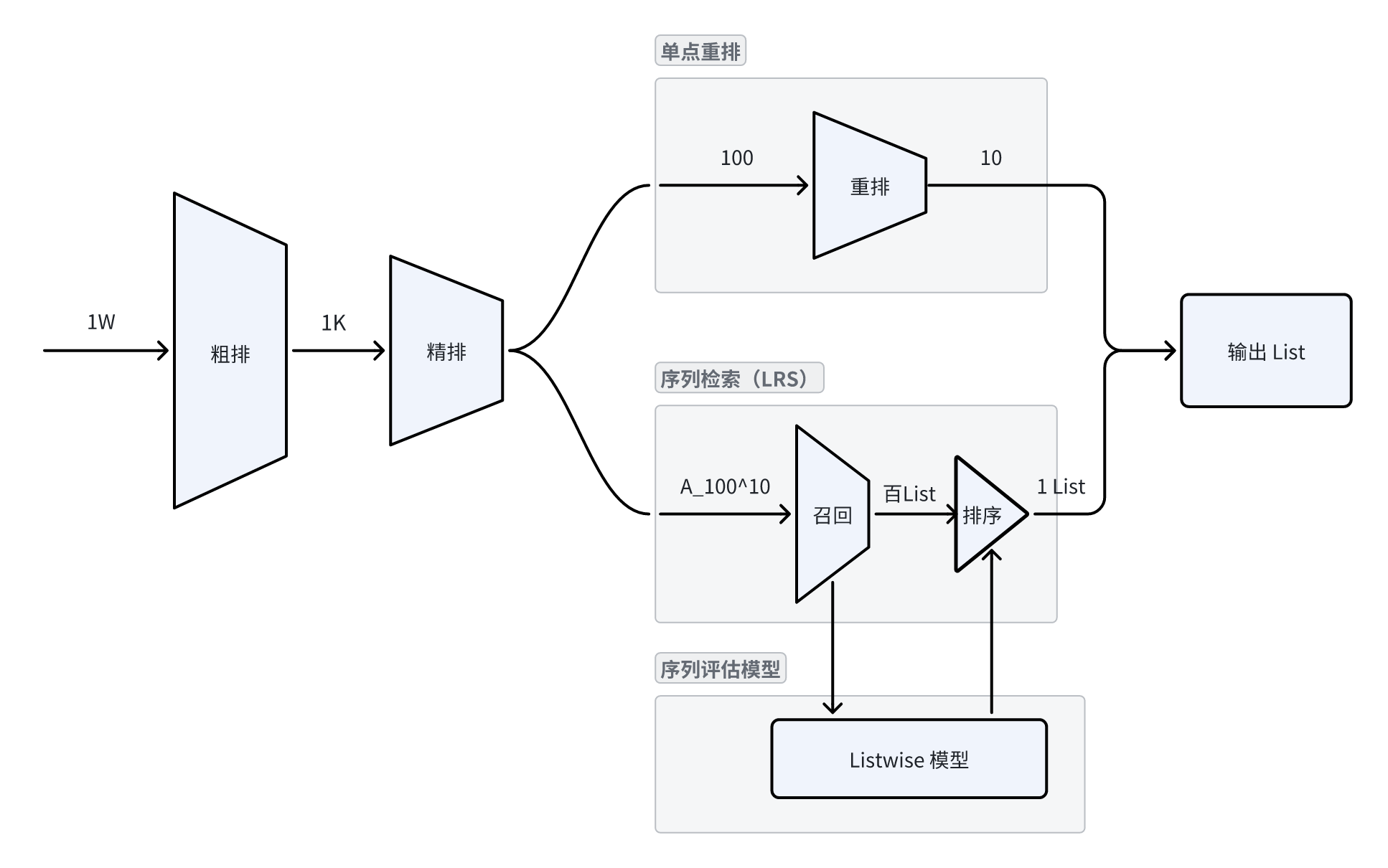
2.3 重排-召回
之所以要有该环节,除了需要让序列的空间分布固定以利于 Listwise 评估外,还有一个重要的假设:传统的贪心重排算法是很难趋向全局最优的。
所以该环节重点是如何生成尽可能高效但又具有差异的序列集合,序列的多和差异是为了增加逼近最优序列的概率。
虽然最优序列我们可能永远做不到,但相比 Base 的单序列(Original List)增加了找到更优 List 的可能,因为一个兜底的做法就是将 Original List 也加入到候选序列集合中。
实际上也是多路召回思路:
- 使用不同的序列生成模型来生成序列;
- 同一序列生成模型下,生成不同目标的序列。
这里介绍几个常用的序列生成模型和如何生成不同目标的序列,其实核心思想就是不同算法生成序列,或同一个算法采用不同的参数来生成。可以想一下,这些生成算法单独应用时,想必有一些调参的工作,现在好了,我们可以把想要的参数都作为一个序列生成的候选。
2.3.1 MMR 模型
MMR 全称 Maximal Marginal Relevance,即最大边界相关法,是一种应用较为广泛的重排模型。
其核心公式如下所示:
相信有不少算法工程师在早期也用过此模型,那可以基于此生成多样的序列候选。一般有 3 种方式:
Lambda的超参数变化,可以生成效率和多样性侧重程度不同的序列;- $Sim_1$ 往往是
效率分,其可以有不同的融合方式,比如更侧重点击、或者订单,如此也可以生产不同的序列; - $Sim_2$ 往往是
多样性分,其也可以有不同的构建方式,比如增强品类差异,削弱序列品牌,或者增加多样性计算窗口等。
而上述三种方式独立使用外,又可以互相叠加,如此一种重排模型便可以生产多种多样的序列。当然数量上也需要控制,主要是出于性能的考虑,所以也需要算法工程师结合业务认识来选取序列生成的配置。
2.3.2 DPP 模型
其是通过构建核矩阵后使用行列式求解的一种算法,逻辑细节不是这里的重点,我们主要看其在生成中对序列价值度量方式:
其中,第一项是效率分的变换,第二项是相似性矩阵的行列式变换。
同样的逻辑,该模型也可以通过修改不同的环节来实现生成不同的序列,如:
- 效率分 $r_{u,i}$ 的融合分方式差异化;
- 相似性 $S_{ij}$ 的构建方式差异化。
2.3.3 Beamsearch
Beam Search (束搜索)是一种在有限集合中寻找最优有序子集的搜索算法。可以简述为:
- 初始 m 个序列;
- 每轮给 m 个序列各选前 k 个最优的且满足业务逻辑的候选 item;
- 从 m x k 个候选序列再选择 m 个序列进入下一轮;
- 重复上述步骤直到序列长度满足要求。
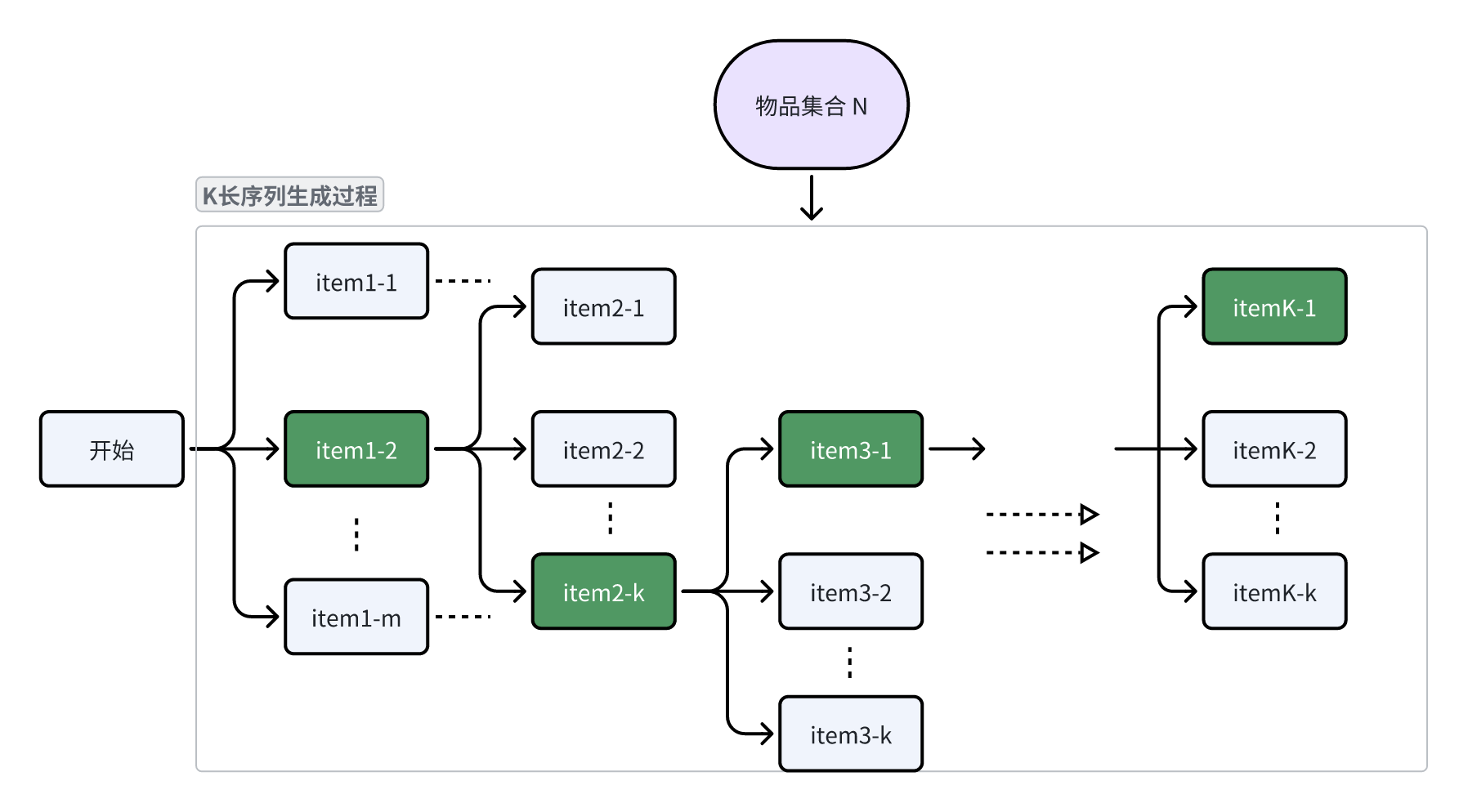
可以看到,该方法实际上是基于贪心算法扩大了搜索范围,涉及调参的环节也很多,都可以作为序列生成的差异化来源。例如:
- 序列个数 m 以及每轮搜索物品数 k;
- 选取物品时依赖的分数,效率分、多样性分等;
- 业务逻辑(如打散)的强弱;
- 首轮种子、中间轮保留序列的评估方式。
2.3.4 GRN
既然经常强调序列重排的时候要关注空间信息,那么参考 NLP 的 seq2seq 结构,如果构建一个深度模型对候选序列循环排序,每轮将已排序的作为 input,似乎能够解此问题。例如 GRN(Generative Reranking Network)就是这样一个探索,模型结构如下图。
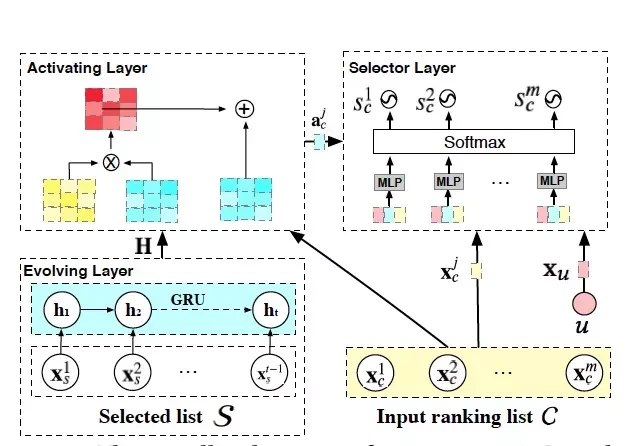
可以看到使用了 GRU 来捕捉序列信息的,当然也有用 Transformer 结构的做法。但不管是结构 ,都是一种 往前看的生成模型,即输入包含前面已经排好的序列。不过这类生产模型有一些缺点:构建和迭代复杂;线上推理时间长;差异化生成复杂度高。
2.4 重排-排序
在重排-召回环节完成之后,我们可以得到了一系列高效且丰富多样的候选 List,一般建议在几十至几百,当然这个主要由场景的价值增益、资源成本等决定。
这些候选 List 可能在物料上有差异,但空间排布上的差异更是重点。所以,对这些 List 的价值预估可以基于精排分设计 Reward 公式,但如果想更精准的预估,就需要进行真正的 Listwise 建模。
思路:要模拟用户浏览时的决策,对于一个物料是否有兴趣,除了精排关注的因素外,其上下的空间排版就至关重要,就需要在特征和模型结构上重点弥补这部分信息。

2.4.1 分位置建模
方法:对已排好序列的每个位置的 item 进行相关目标的预估。例如 pctr、pcvr 等,目标就是比精排预估得更准。
优势:
- 逻辑简单,利用空间排版特征、Listwise 模型结构来弥补精排不足;
- 方便评估,可直接与精排进行 AUC 等指标对比;
- 兼容性高,下游度量序列价值的融合公式往往不用修改。
缺点:非整序列建模,依然通过对每个 item 进行预估。
2.4.2 整序列建模
与分位置建模对应的就是整序列建模,即 Label 不再是序列中每个 item 的业务价值,而是整个序列的。比如,分位置建模 ctr(点击率) 就可以变成对整序列建模 ipv(点击数)。
但是,在这里有一个不同点:
- 分位置的时候,Label 还是可以对齐精排,如 ctr 使用 sigmoid 做二分类任务;
- 整序列建模的时候,Label 往往就不是二值的了,不能简单的做二分类,会损失信息。
解法:分层多分类。
以 ctr 对应的 ipv 为例,假设序列长度为 n,ctr 的 Label 为 0/1,那么 ipv 的 Label 范围就是 0-n,这 n+1 种可能。
那么就可以在每两个取值之间作为分割点,构建二分类任务,总计 n 个。
比如,第 $i (1<= i <= n)$ 个 Label 就是:1
2
3
4Label_i = \begin{cases}
0 &\text{if } ipv<i \\
1 &\text{if } ipv>=i
\end{cases}
如果这 n 个分层 Label 的预估项为$p_i,i \in [1,n]$,那么最后 ipv 的预估项应该为:
其中,最后一项中 $p_{n+1}=1$即可。
2.4.3 评估目标
评估目标的设立,依赖前述对业务建模的目标,最后进多目标之间的融合评估,这点与精排环节类似。
一般可能会涉及,曝光PV,点击IPV,转化ORD,多样性DIV,客单价AOV,停留时长TIME等。
这里重点介绍2个具有代表性的,点击IPV,多样性DIV。
点击IPV
这是一个比较明确的统计量,用户的点击次数。
该指标具有局部累加性:即每个请求贡献的 IPV 是可以直接累积到整体的,不会有衰减。
一个建议的构建方式是:
其中,$p^{expose}$ 是曝光概率,可以是模型预估的,如没有可以去掉或者用离线统计代替。
当然,这里针对的是分位置建模,如果是整序列建模,则对应的 $p^{ipv}$ 在上述已介绍。
多样性DIV
相对于上面而言,该指标需要依赖业务来明确具体的统计量是什么。
且往往不具有局部累加性,比如用户点击的类目数,它是有一个 user 维度去重的概念。
这种情况比较复杂,可以尝试下面2种。
类目信息熵:
其中,$p{cid}$是对应 cid 类目的占比,$ctr{cid}$则是该类目的点击率某统计量,比如均值等。
未点击类目期望:
其中,isnew 是指当前 cid(类目id)是否是 user 未点击的,$ctr{cid}$同样是一个统计量,可以采用反概率:$ctr{cid}=1 - \prod_{i} (1 - p^{ctr}_i)$。
需要强调的是:真正是否有效,与数据的分布、业务的逻辑等有很大关系,需要结合具体业务理解来尝试和优化,以实验反馈为准。
3 实战思考
在实际落地应用中,实际上有很多的坑需要踩,这里将结合自己的一些实践经历,总结一些相对比较重要的细节,供大家参考和自己复习。
3.1 序列生成的多样性
在重排-召回环节我们提到需要生成丰富多样的候选序列,那么这其中一个便是序列的多样性。当然,具体多样性是指什么,需要根据实际业务场景来,比如:
- 电商的品牌、品类、店铺等;
- 视频的作者、类型、演员等;
- 图文的作者、主题、风格等。
在重排中,往往会有一个多样性的设置,一般是 hard 规则(兜底) + soft 度量(排序)。其中 soft 度量多样性的部分,以 MMR 为例,会有2个要素:
- 物品间多样性计算方式。比如 embedding cos、属性 match 等;
- 物品选择时多样性统计窗口。比如 MMR 每轮多样性分数的统计窗口,即往前看多少个物品。
在多样性计算方式上:
- 属性
match简单且往往有效,但维度的选择一定要根据业务场景来,要选用户关注的多样性维度; - 使用
embedding cos,需要注意 embedding 的生成方式,用户关注的多样性维度要体现在其中,反之像基于行为训练的往往会不尽如意; - 一般建议结合
embedding cos+ 属性match的方式; - 多样性不同属性维度的权重可以作为序列生成的差异性来源。
在多样性统计窗口上:
- 离当前 item 越近的权重可以设置越高;
- 窗口的大小可以作为序列差异性的来源,往往比较有效。
3.2 “Beamsearech+X”序列生成框架
Beamsearch 是束搜索,它是对穷举搜索和贪心搜索这两种偏极端算法的一种折中之策。即在每一轮选择候选的时候,既不是贪心的只选得分最高的,也不是穷举得遍历每种组合,而是选择 topK 个候选增加寻到更优 List 的可能性,具体算法细节这里不再赘述。
这里笔者重点想介绍的是基于其构建的一种拓展方案,即“Beamsearech+X”序列生成框架。怎么理解呢?
前面提到 Beamsearch 主要是在每轮选取的时候拓展了候选,增加靠近全局最优的可能性。但,需要注意的是,在每一轮选取的时候依然需要有一个 Function 来度量候选加入后对 List 的影响好坏。而 Function 的构建实际上就退化成了单 List 的排序,这部分有一些成熟的候选:
- 效率分贪心;
- MMR;
- DPP等。
于是,上面的候选算法都可以作为 Beamsearch+X 中的 X 项。
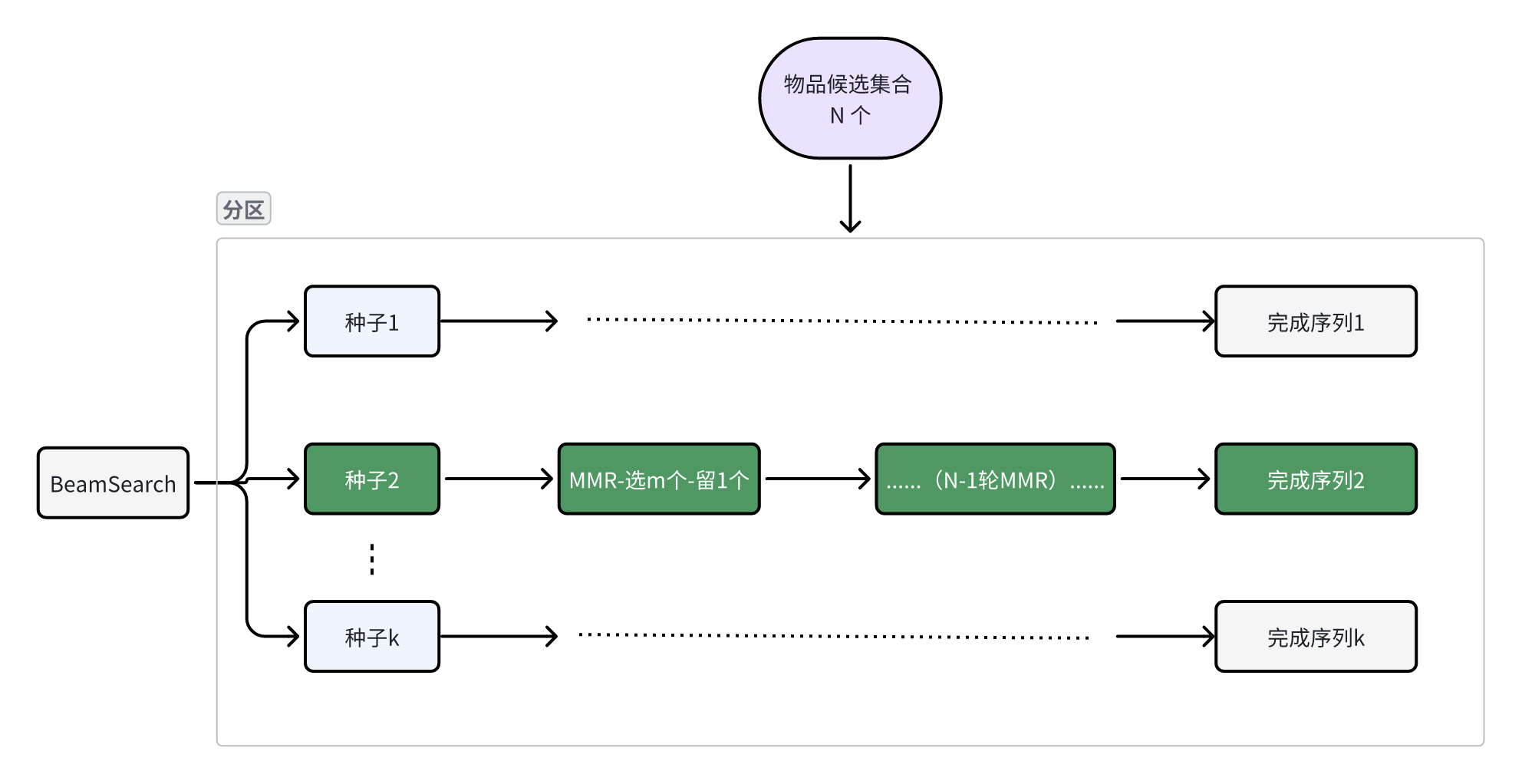
我们以 MMR 为例,如上图所示是一种 Beamsearch+MMR 实现方案:
种子选取:根据物品分 Score 选取 K 个作为 List 种子;生成候选:中间每轮,为每个种子 List 选取 M 个候选,例如使用 MMR;序列子评估:从每个种子的 M 个候选 List 中选择一个整体价值最高的保留;完成序列:重复上述直到序列长度满足业务要求,将序列集合作为该路召回。
如此,其他的单序列生成都可以融入到 Beamsearch+X 体系中,拓展生成能力。那么 Beamsearch+X 的召回丰富度,除了可以继承 X 生成算法的丰富度调整方式外,Beamsearch 本身的一些特征也可以作为调整项,比如:
- 种子物品的选取方式,如效率 topK、多样性 topK等;
- 种子个数 K、每轮候选 M;
- 子评估的构建方式,如统计、LR等;
- 子评估的排序方式,比如子序列候选混合或独立。
3.3 候选评估模型
在序列生成环节,前述提到的 MMR、Beamsearch+X、DPP等均是动态规划类或搜索类模型,并不是一个真正训练得到的排序模型。
当然,GRN 类的 Seq2Seq 模型属于训练得到的深度模型,但往往难以覆盖广泛的序列召回需要,并且性能容易陷入瓶颈。
在序列生成每轮检索候选时,也是可以通过构建一个简单的模型来代替的,如下图所示:
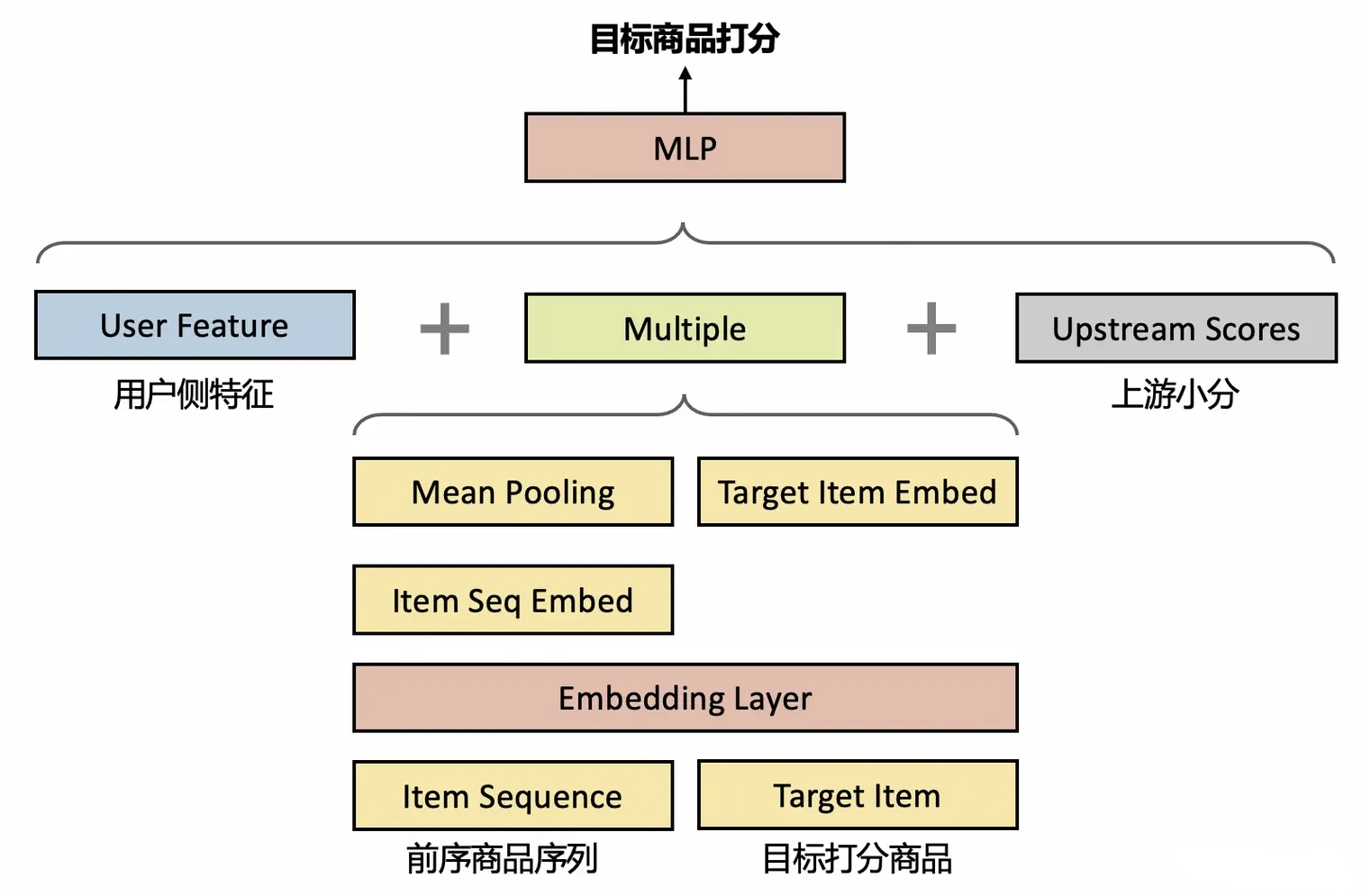
生成的时候,没有办法同时考虑上文和下文,往往只有上文,即已经排序好的 List 部分。故,就可以将前序物品序列作为主要的 input 信息,然后评估候选物品加入后的效率。如此构建一个有监督模型。但往往要注意性能,因为在生成的时候,要多轮调用,所以一般建议使用简单的 LR 模型即可。
3.4 Listwise 特征设计
前面介绍过重排与精排的差异及其目标,所以在这里的特征设计上,我们要结合上述2点来考虑:
上游特征的使用:- 例如精排分,召回渠道,供给分布等;
- 此处非常重要,一方面是不浪费推荐系统上游的产出,另一方面也是重排环节效果>=精排的保障。
空间分布的特征:- 例如窗口类目分布等,可以是前置窗口,也可是后置,当然前后横跨的窗口也是需要的;
- 这部分是重排模型的核心差异和优势之处,对这部分信息的捕捉好决定了重排效果增益空间。
这里有一个风险:如果使用不当,容易对上游精排分数等形成强依赖,使得系统上下游耦合过重。
如,过度依赖精排分,如果其因迭代带来分数分布明显变化,容易直接带崩重排,从而让重排成为精排迭代的一个限制。
分析原因:带崩往往是由于分数分布变化,出现一些重排没见过的特征值。
解法思路:分布可以变化,但新特征值/量纲跨越要尽量少,故可对上游特征进行脱敏。
比如将原始分,归一化,分段,取分位点等等,以此尽量捕捉有效信息的同时,避免因分值变化而带来新特征值爆发、量纲跨越等问题。
参考文章:
LTR (learning to Rank) 在互联网中目前发展如何?
KDD23|RankFormer:用Transformer去做LTR任务
ListNet和ListMLE
KDD’23 | 阿里, 排序和校准联合建模: 让listwise模型也能用于CTR预估
Generator-Evaluator重排模型在淘宝流式场景的实践
序列检索系统在淘宝首页信息流重排中的实践
渠江涛:重排序在快手短视频推荐系统中的演进
算法实践总结V3:重排在快手短视频
同城多样性算法在部落的实践和思考
排序优化算法Learning to Ranking
Learning to Rank : ListNet与ListMLE