
1 背景
如果你是一个玩深度学习的算法工程师,那么相信你对批标准化(Batch Normalization)一定不陌生。在实际训练深度模型中,BN 往往用来加速模型收敛或者缓解梯度消失/爆炸的问题。笔者在实际使用过程中也有一定的收获和思考,收获是不同的使用姿势确实能够带来不一样的效果。思考就是,虽然大致知道BN的原理和公式,但是创建 BN 这个方法的出发点和一些边界问题的思考始终萦绕在周围。在此做一个汇总整理,旨在帮助和我一样有此困惑的朋友们。
2 原理
2.1 优化原理
训练网络深度的加深可能会带来梯度迭代上的梯度消失(Gradient Vanishing)或者梯度爆炸(Gradient Explore)问题。这两个问题的产生原理这里不做赘述,一般都是由于网络层数过深,梯度链式传导带来的结果。
网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,所以一般只能选取较低的学习率和较小值来初始化。这种分布的变化一般称之为internal covariate shift。
Convariate Shift是指训练集的样本数据和目标样本集分布不一致时,训练得到的模型无法很好的Generalization。
在训练网络模型的时候经常会对输入做均值归0化,有的做白化,都是为了加速训练。但是能够加速的原理是什么呢?
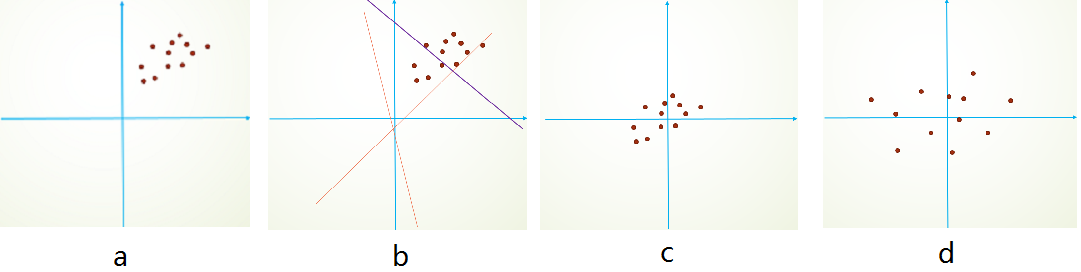
如上图所示,假设初始的样本数据分布如图a所示。当我们进行模型拟合的时候,以单层网络$y = Wx+b$为例,由于参数初始化的时候都是0均值附近的很小值,所以拟合曲线一般都会过原点,如上图 b 红色虚线所示,想要达到收敛的情况就会比较慢。但是,如果将数据平移至原点附近,如图 c 所示,陷入可以加快拟合速度。更甚者对数据做去相关,如图 d 所示,样本间的区分度就会更高。
而做标准化的方式也有多种,效果比较好的是PCA,但是在复杂的网络中需要计算协方差矩阵、求逆等操作,计算量很大,此外,反向传播时,标准化操作不一定可导。这时候Batch Normalization的优势就体现了出来。
Bactch Normalization是来标准化某些层或者所有层的输入,从而固定每层输入信息的均值和方差。一般就是要让数据具有0均值和单位方差:
公式中的均值和方差,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
但是,如果仅仅这么简单的做是有问题的。
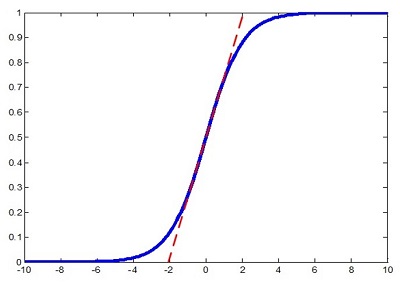
我们以下图常用的激活函数sigmoid为例,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。
所以,就可以在上述的基础上,增加一个平移和缩放的变换,用来保持模型的表达能力:
2.2 模型推理
实际使用的时候,模型前向传输网络依然使用下列的公式进行数据的标准化:
注意:这里的$E[x]$和$Var[x]$不同于训练时候的值,并不是当前batch的统计结果,而是针对整个数据集的统计值。
但是,怎么获取呢?
- 训练时,均值、方差分别是该批次内数据相应维度的均值与方差;
- 推理时,均值、方差是基于所有批次的期望计算所得:
为了最后在模型 infer 过程中更加准确,需要记录每一个训练的Batch的均值和方差,其实就是一个无偏估计:
大部分经验说应该把BN放在激活函数之前,这是因为:
- 本身就是为了解决梯度消失/爆炸的问题;
- $Wx+b$具有更加一致和非稀疏的分布。
但是也有人做实验表明放在激活函数后面效果更好。
3 tf实战
介绍了那么多理论,那实际中如何在网络中使用BN层呢?这里将介绍一些对应的tensorflow的API以及使用的小Tips。
3.1 BN 的 API
首先Batch Normalization在TensorFlow中有三个接口调用 (不包括slim、Keras模块中的),分别是:
tf.layers.batch_normalization和tf.contrib.layers.batch_norm可以用来构建待训练的神经网络模型,而tf.nn.batch_normalization一般只用来构建推理模型,原因是后者只定义了初始的网络结构,没有考虑训练和推理时候的参数更新问题。由于tf.contrib包的不稳定性,一般实际中使用最多的就是tf.layers.batch_normalization。
首先,看一下tf.layers.batch_normalization接口方法的定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26tf.layers.batch_normalization(
inputs,
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(),
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
training=False,
trainable=True,
name=None,
reuse=None,
renorm=False,
renorm_clipping=None,
renorm_momentum=0.99,
fused=None,
virtual_batch_size=None,
adjustment=None
)
其中,有几个主要参数需要了解一下:
axis的值取决于按照input的哪一个维度进行BN,例如输入为channel_last format,即[batch_size, height, width, channel],则axis应该设定为4,如果为channel_first format,则axis应该设定为1.momentum的值用在训练时,滑动平均的方式计算滑动平均值moving_mean和滑动方差moving_variance。center为True时,添加位移因子beta到该BN层,否则不添加。添加beta是对BN层的变换加入位移操作。注意,beta一般设定为可训练参数,即trainable=True。scale为True是,添加缩放因子gamma到该BN层,否则不添加。添加gamma是对BN层的变化加入缩放操作。注意,gamma一般设定为可训练参数,即trainable=True。training表示模型当前的模式,如果为True,则模型在训练模式,否则为推理模式。要非常注意这个模式的设定!!!,这个参数默认值为False。如果在训练时采用了默认值False,则滑动均值moving_mean和滑动方差moving_variance都不会根据当前batch的数据更新,这就意味着在推理模式下,均值和方差都是其初始值,因为这两个值并没有在训练迭代过程中滑动更新。
3.2 BN 的 code
TensorFlow中模型训练时的梯度计算、参数优化等train_op并没有依赖滑动均值moving_mean和滑动方差moving_variance,则moving_mean和moving_variance不会自动更新,只能在tf.GraphKeys.GLOBAL_VARIABLES中,所以必须加入负责更新这些参数的update_ops到依赖中,且应该在执行前向计算结束后、后向计算开始前执行update_ops,所以添加依赖的位置不能出错。在前文提到的$\beta$和$\gamma$是可训练变量,存放于tf.GraphKeys.TRAINABLE_VARIABLES。实际中,只需要在构建模型代码中,添加完所有BN层之后获取update_ops就不会出错!!!这是TensorFlow的图计算模式造成的编程影响,在其他深度学习框架中可能会有差别。
训练1
2
3
4
5x_norm = tf.layers.batch_normalization(x, training=True)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
train_op = optimizer.minimize(loss)
train_op = tf.group([train_op, update_ops])
模型保存1
2
3sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
saver.save(sess, "your_path")
预测1
2
3
4x_norm = tf.layers.batch_normalization(x, training=False)
saver = tf.train.Saver(tf.global_variables())
saver.restore(sess, "your_path")
estimator
如果你使用的是高阶API:estimator进行训练的话,那么就比较麻烦,因为它的session没有暴露出来,你没办法直接使用,需要换个方式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83def model_fn_build(init_checkpoint=None, lr=0.001, model_dir=None):
def _model_fn(features, labels, mode, params):
x = features['inputs']
y = features['labels']
#####################在这里定义你自己的网络模型###################
x_norm = tf.layers.batch_normalization(x, training=mode == tf.estimator.ModeKeys.TRAIN)
pre = tf.layers.dense(x_norm, 1)
loss = tf.reduce_mean(tf.pow(pre - y, 2), name='loss')
######################在这里定义你自己的网络模型###################
lr = params['lr']
######################进入eval和predict之前,都经过这一步加载过程###################
# 加载保存的模型
# 为了加载batch_normalization的参数,需要global_variables
tvars = tf.global_variables()
initialized_variable_names = {}
if params['init_checkpoint'] is not None or tf.train.latest_checkpoint(model_dir) is not None:
checkpoint = params['init_checkpoint'] or tf.train.latest_checkpoint(model_dir)
(assignment_map, initialized_variable_names
) = get_assignment_map_from_checkpoint(tvars, checkpoint)
tf.train.init_from_checkpoint(checkpoint, assignment_map)
# tf.logging.info("**** Trainable Variables ****")
# for var in tvars:
# init_string = ""
# if var.name in initialized_variable_names:
# init_string = ", *INIT_FROM_CKPT*"
# tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
# init_string)
######################进入eval和predict之前,都经过这一步加载过程###################
if mode == tf.estimator.ModeKeys.TRAIN:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
train_op = optimizer.minimize(loss)
train_op = tf.group([train_op, update_ops])
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
if mode == tf.estimator.ModeKeys.EVAL:
metrics = {"accuracy": tf.metrics.accuracy(features['label'], pred)}
return tf.estimator.EstimatorSpec(mode, eval_metric_ops=metrics, loss=loss)
predictions = {'predictions': pred}
predictions.update({k: v for k, v in features.items()})
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
return tf.estimator.Estimator(_model_fn, model_dir=model_dir, config=config,
params={"lr": lr, "init_checkpoint": init_checkpoint})
def get_assignment_map_from_checkpoint(tvars, init_checkpoint):
"""Compute the union of the current variables and checkpoint variables."""
assignment_map = {}
initialized_variable_names = {}
name_to_variable = collections.OrderedDict()
for var in tvars:
name = var.name
m = re.match("^(.*):\\d+$", name)
if m is not None:
name = m.group(1)
name_to_variable[name] = var
init_vars = tf.train.list_variables(init_checkpoint)
assignment_map = collections.OrderedDict()
for x in init_vars:
(name, var) = (x[0], x[1])
if name not in name_to_variable:
continue
assignment_map[name] = name
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1
return (assignment_map, initialized_variable_names)
3.3 一些总结
笔者在使用中有一些对比结论:
- 首先 bn 层往往放在 dense 层和 activation 层(一般 ReLU)之间,有助于加速收敛和防止过拟合;
- 尽量不在 sigmoid 的激活层前加,可能会使得模型难以收敛;
- 输出层之前一般不能加;
- training 的参数及其重要。
参考文章
解读Batch Normalization
[TensorFlow 学习笔记-05]批标准化(Bacth Normalization,BN)
tensorflow中batch_normalization的正确使用姿势
Batch Normalization的正确打开方式
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift