20.【深度学习】深度学习在推荐系统中的应用有哪些
深度学习与推荐系统
在矩阵分解中,原始的矩阵表示每个用户的向量是物品,表示每个物品的向量是用户,两者向量的维度都特别高不说,还特别稀疏,分解后用户向量和物品向量不但维度变得特别小,而且变稠密了。业界还把这个稠密的向量叫做隐因子,意图直观说明它的物理意义:用户背后的偏好因子,物品背后的主题因子。
实际上,你完全可以把矩阵分解看成是一种浅层神经网络,只有一层,它的示意图如下。
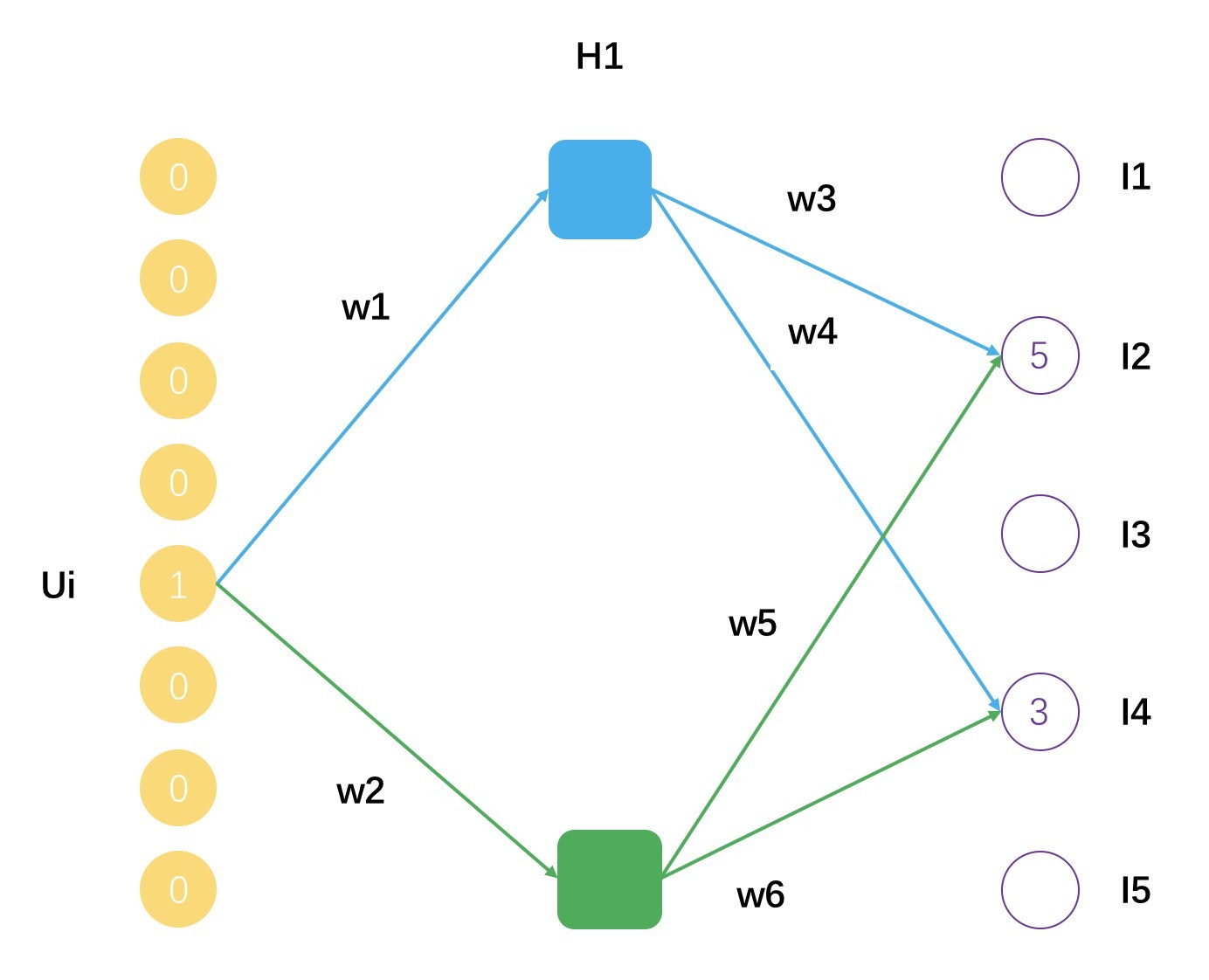
这个示意图表示了一个用户 Ui,评分过的物品有 I2 和 I4,分解后的矩阵隐因子数量是 2,用户 Ui 的隐因子向量就是 [w1, w2],物品 I2 的隐因子向量是 [w3, w5],物品 I4 的隐因子向量是 [w4, w6]。可以把矩阵分解看成是一个拥有一个隐藏层的神经网络,得到的隐因子向量就是神经网络的连接权重参数。
深度学习是对事物的某些本质属性的挖掘,有两个好处:
- 可以更加高效且真实地反映出事物本身的样子。对比一下,一张图片用原始的像素点表示,不但占用空间大,而且还不能反应图片更高级的特征,如线条、明暗、色彩,而后者则可以通过一系列的卷积网络学习(CNN)而得。
- 可以更加高效真实地反映出用户和物品之间的连接。对比一下,以用户历史点击过的物品作为向量表示用户兴趣;用这些物品背后隐藏的因子表示用户兴趣,显然后者更高效更真实,因为它还考虑了物品本身的相似性,这些信息都压缩到隐因子向量中了,同时再得到物品的隐因子向量,就可以更加直接平滑地算出用户对物品的偏好程度。
这两个好处,正是深度学习可以帮助推荐系统的地方。第一个叫做 Embedding,就是嵌入,第二个叫做 Predicting,就是预测。 其实两者在前面的内容都已经有涉及了,矩阵分解得到的隐因子向量就是一种 Embedding, Word2vec 也是一种 Embedding,Wide&Deep 则是用来预测的。关于第二种,具体来说有几个方向:深度神经网络的 CTR 预估,深度协同过滤,对时间序列的深度模型。
各种 2vec
首先还是在文本领域,从 Word2vec 到 Sentence2vec,再到 Doc2vec。简单介绍一下 Word2vec。你知道,Word2Vec 最终是每个词都得到一个稠密向量,十分类似矩阵分解得到的隐因子向量,得到这个向量有两个训练方法。先说第一个方法,想象你拿着一个滑动窗口,在一篇文档中从左往右滑动,每一次都有 N 个词在这个窗口内,每移动一下,产生 N-1 条样本。
每条样本都是用窗口内一个词去预测窗口正中央那个词,明明窗口内是 N 个词,为什么只有 N- 1 条样本呢?因为正中央那个词不用预测它本身啊。这 N-1 条样本的输入特征是词的嵌入向量,预测标签是窗口那个词。示意图如下所示:
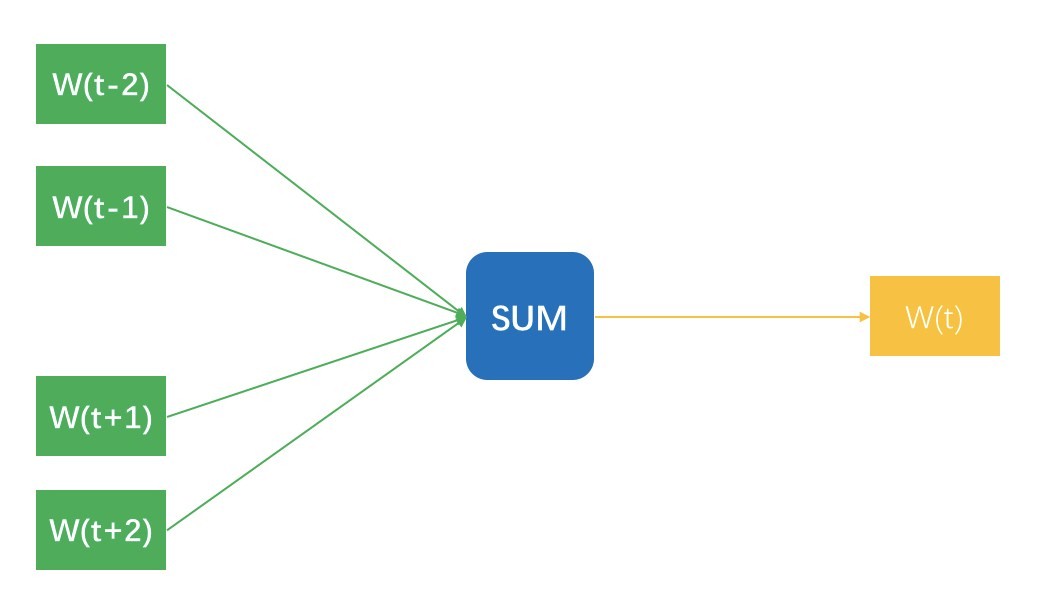
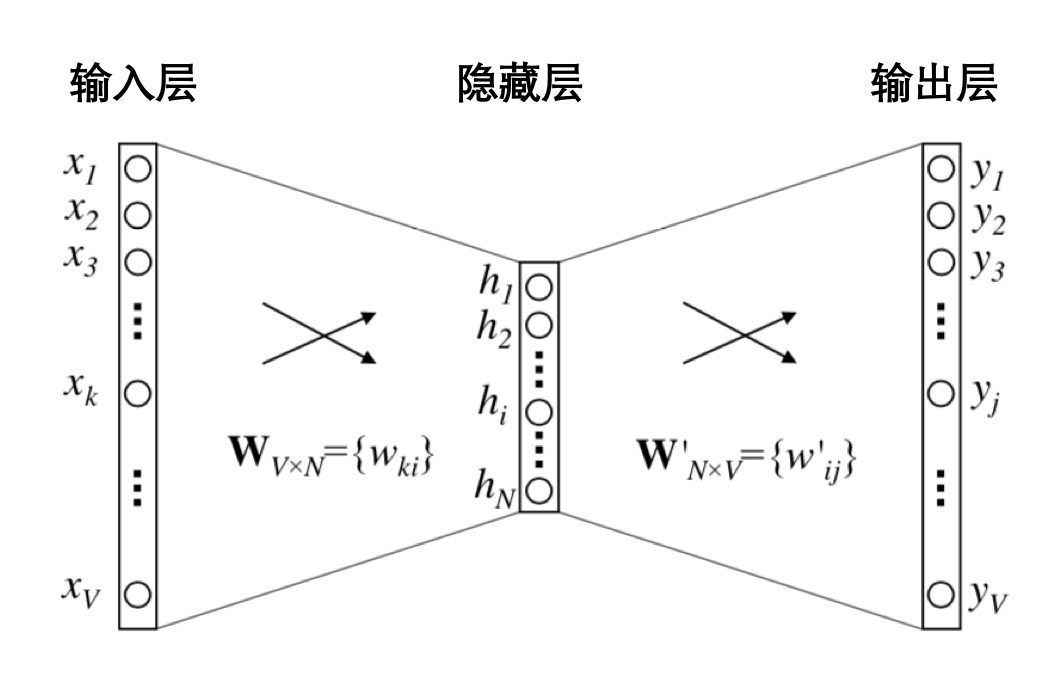
图中把 N-1 个样本放在一起示意的,无法看出隐藏层,实际上,输入时每个词可以用 One-hot 方式表示成一个向量,这个向量长度是整个词表的长度,并且只有当前词位置是 1,其他都是 0。
隐藏层的神经元个数就是最终得到嵌入向量的维度数,最终得到的嵌入向量元素值,实际上就是输入层和隐藏层的连接权重。示意图如下:
至于 Word2vec 的第二种训练方法,则是把上述的 N-1 条样本颠倒顺序,用窗口中央的词预测周围的词,只是把输入和输出换个位置,一样可以训练得到嵌入向量。这就是两大经典训练方法,CBOW和Skip-Gram。
既然词可以表示成一个稠密向量干这干那,那不如来个 Sentence2vec,把一个句子表示成一个嵌入向量,通常是把其包含的词嵌入向量加起来就完事了。
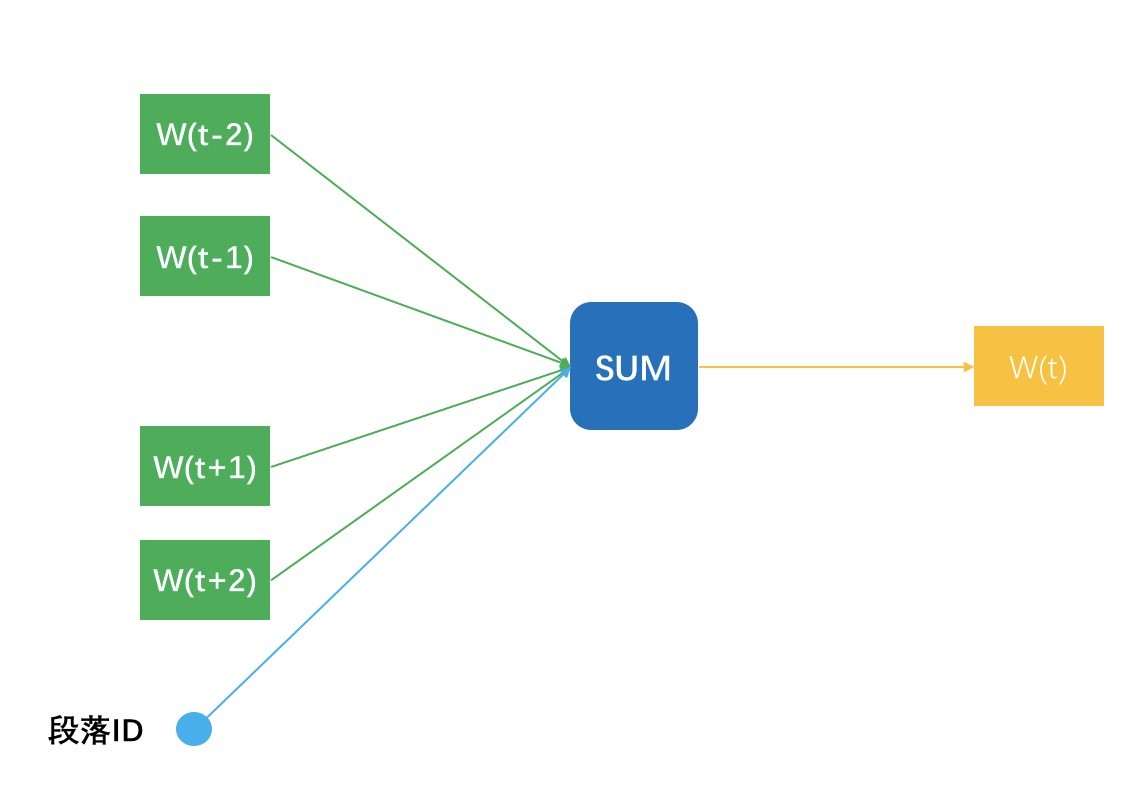
而 Doc2vec 则略微一点点不同,说明一点,多个句子构成一个段落,所以这里的 Doc 其实就是段落。Doc2vec 在窗口滑动过程中构建 N-1 条样本时,还增加一条样本,就是段落 ID 预测中央那个词,相当于窗口滑动一次得到 N 条样本。一个段落中有多少个滑动窗口,就得到多少条关于段落 ID 的样本,相当于这个段落中,段落 ID 在共享嵌入向量。段落 ID 像个特殊的词一样,也得到属于自己的嵌入向量,也就是 Doc2vec。
那么对于Product2vec就是照着词嵌入的做法来,把用户按照时间先后顺序加入到购物车的商品,看成一个一个的词,一个购物车中所有的商品就是一个文档;于是照猫画虎学出每个商品的嵌入向量,用于去做相关物品的推荐,或者作为基础特征加入到其他推荐排序模型中使用。类似的,如果是应用商场的 App 推荐,也可以依计行事,把用户的下载序列看成文档,学习每个 App 的嵌入向量。
各种 2vec 的做法其实还不算深度学习,毕竟隐藏层才一层而已。如果要用更深的模型学习嵌入向量,就是深度学习中的 AutoEncoder,自动编码器。
从输入数据逐层降维,相当于是一个对原始数据的编码过程,到最低维度那一层后开始逐层增加神经元,相当于是一个解码过程,解码输出要和原始数据越接近越好,相当于在大幅度压缩原始特征空间的前提下,压缩损失越小越好。
YouTube 视频推荐
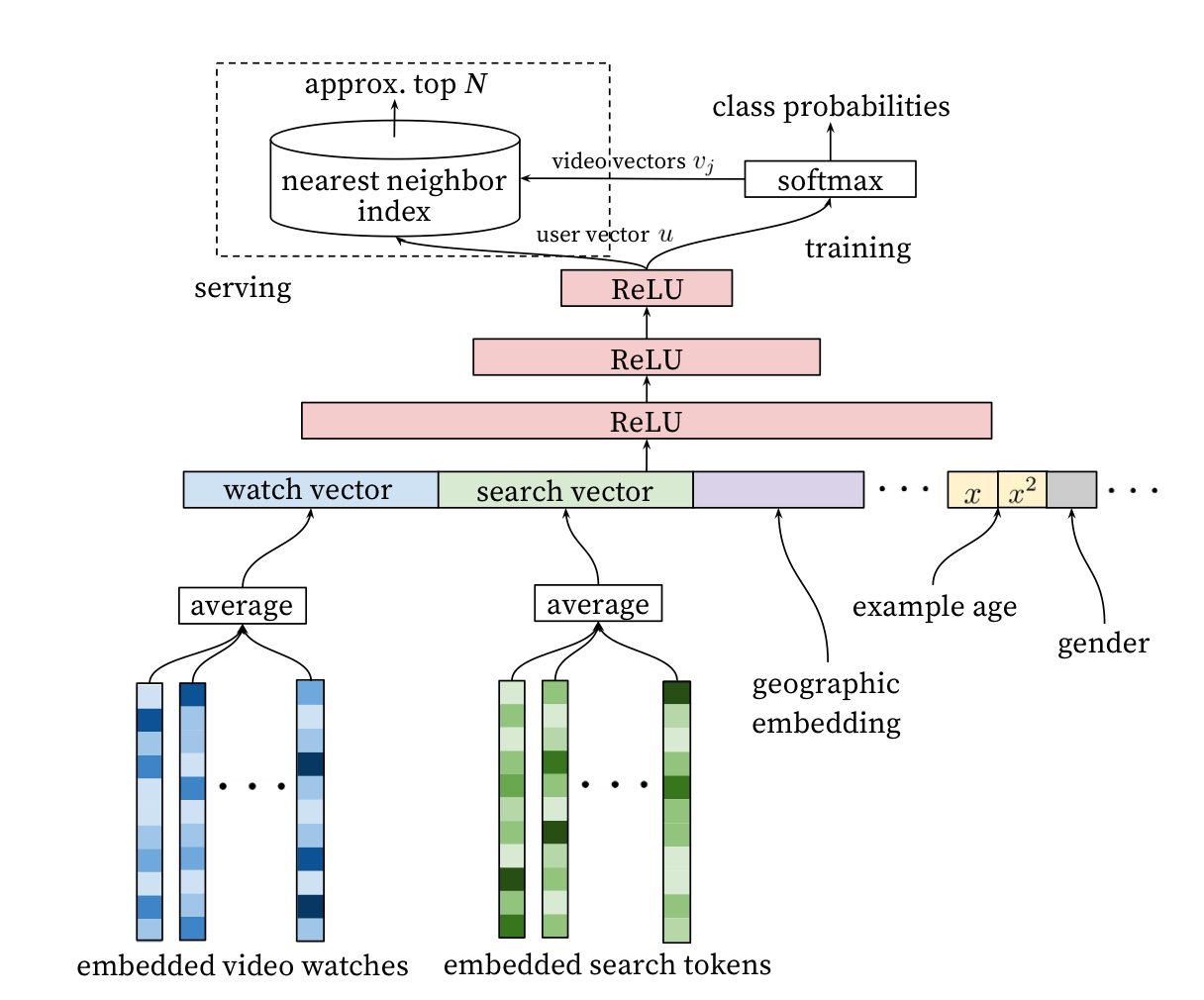
首先,Youtube 把推荐的预测任务看成是一个多分类,这个和之前常规的推荐系统要么预测行为要么预测评分的做法不太一样,而是把候选物品当成多个类别,预测用户下一个会观看哪个视频。
这个公式中 U 是用户 C 是场景,输入时视频的嵌入向量和用户的嵌入向量。这里就涉及了先要使用深度神经网络,从用户历史反馈行为和场景信息中学习物品和用户的嵌入向量。整个推荐排序模型示意图如下:
原文可以参考:Deep Neural Networks for YouTube Recommendations
- 根据观看历史把视频变成了嵌入向量,然后平均后作为输入特征之一,这个和前面的
Product2vec 的思路一致,把观看历史看成文档,观看的视频看成词。- 搜索 Query 也变成了嵌入向量,平均之后作为输入特征之二。
- 人口统计学信息统统都嵌入了。
- 还加入视频的年龄信息,也就是在预测时,视频上传多久了。
- 所有这些不同的嵌入向量拼接成一个大的输入向量,经过深度神经网络,在输出层以
Softmax 作为输出函数,预测下一个观看视频。
在模型训练时,以 Softmax 作为输出层,但是在实际线上预测服务时,由于模型关心相对顺序,所以并不需要真的去计算 Softmax,而是拿着用户的特征向量做近似的近邻搜索,只生成最相近的一些推荐结果。整个推荐系统非常好理解,也比较好落地,所有的模型都可以通过 TensorFlow 快速实现。
【深度学习】用RNN构建个性化音乐播单
前面讲到的绝大多数推荐算法,也都没有考虑“用户在产品上作出任何行为”都是有时间先后的。有一些矩阵分解算法考虑了时间属性,比如 Time-SVD;但是,这种做法只是把时间作为一个独立特征加入到模型中,仍然没有给时间一个正确的处理方式。
时间的重要性
绝大数推荐算法都忽略操作的先后顺序,为什么要采取这样简化的做法呢?因为一方面的确也能取得不错的效果,另一方面是深度学习和推荐系统还迟迟没有相见。在深度学习大火之后,对时间序列建模被提上议事日程,业界有很多尝试,今天以 Spotify 的音乐推荐为例,介绍循环神经网络在推荐系统中的应用。
循环神经网络
循环神经网络,也常被简称为 RNN,是一种特殊的神经网络。再回顾一下神经网络的结构,示意图如下:
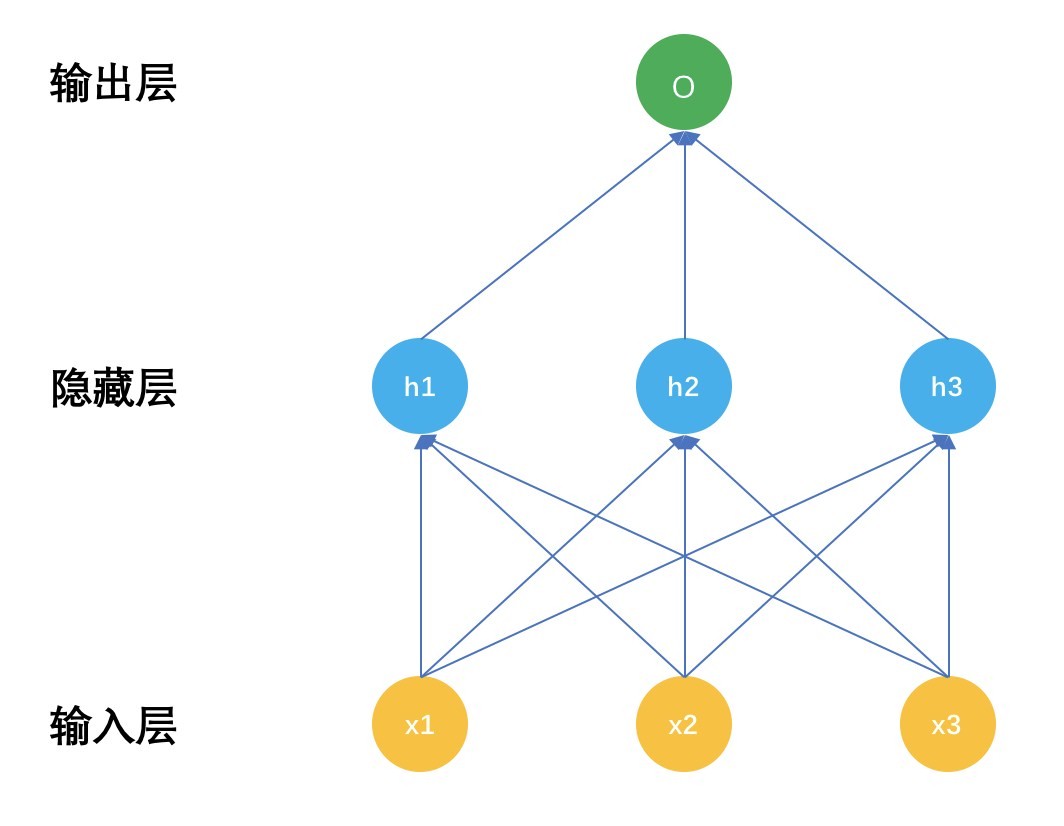
普通神经网络有三个部分,输入层 x,隐藏层 h,输出层 o,深度神经网络的区别就是隐藏层数量有很多,具体多少算深,这个可没有定论,有几层的,也有上百层的。
把输入层和隐藏层之间的关系表示成公式后就是:
就是输入层 x 经过连接参数线性加权后,再有激活函数 F 变换成非线性输出给输出层。
在输出层就是:
隐藏层输出经过输出层的网络连接参数线性加权后,再由输出函数变换成最终输出,比如分类任务就是 Softmax 函数。
循环神经网络和普通神经网络的区别就在于:普通神经网络的隐藏层参数只有输入 x 决定,因为当神经网络在面对一条样本时,这条样本是孤立的,不考虑前一个样本是什么,循环神经网络的隐藏层不只是受输入 x 影响,还受上一个时刻的隐藏层参数影响。
循环神经网络表示成示意图如下:
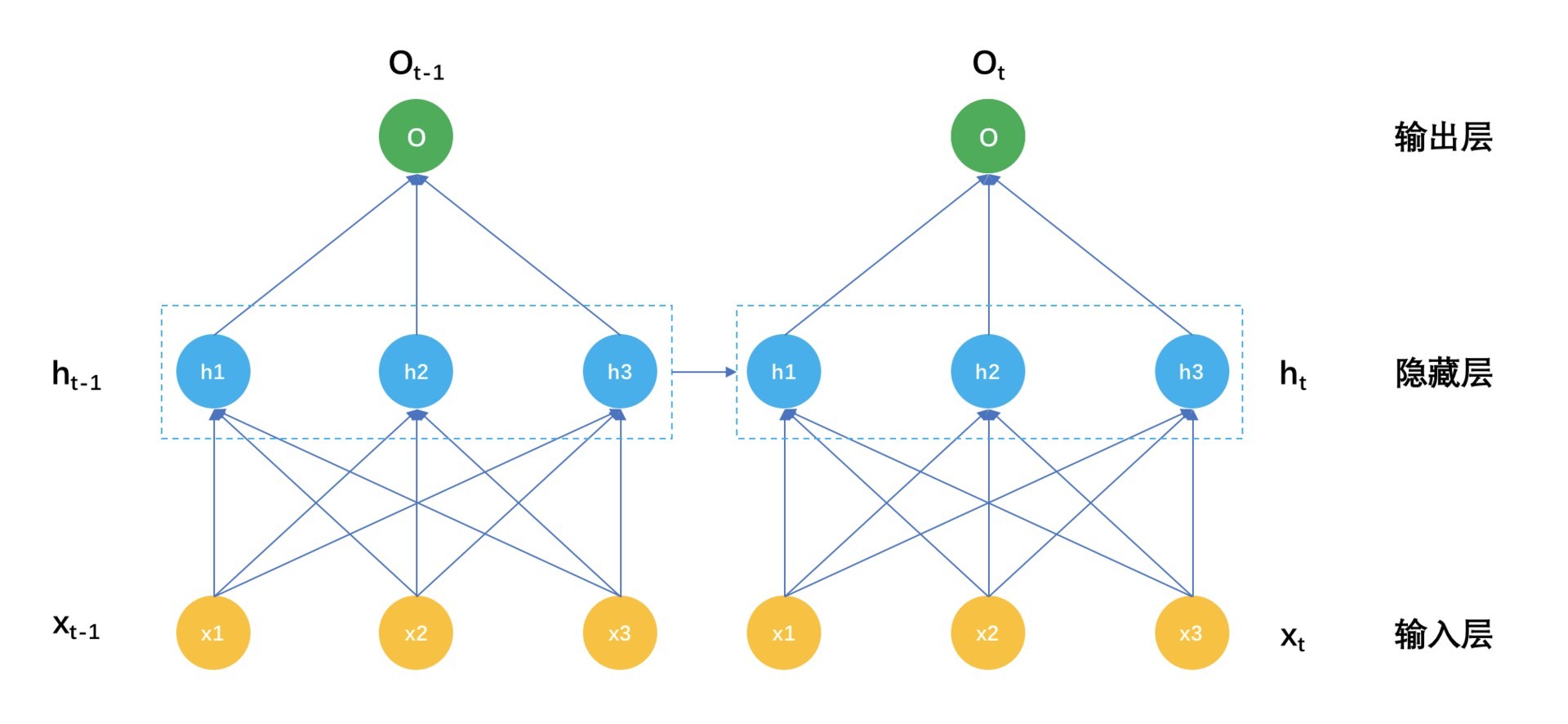
解释一下这个示意图。在时刻 t,输入是 xt,而隐藏层的输出不再是只有输入层 $xt$,还有时刻 t-1 的隐藏层输出 $h{t-1}$,表示成公式就是:
对比这个公式和前面普通神经网络的隐藏层输出,就是在激活函数的输入处多了一个 $Uh_{t-1}$ 。别小看多这一个小东西,它背后的意义非凡。那么上一个时刻得到的隐藏层,就是对时间序列上一个时刻的信息压缩,让它参与到这一个时刻的隐藏层建设上来,物理意义就是认为现在这个时刻的信息不只和现在的输入有关,还和上一个时刻的状态有关。这是时间序列本来的意义,也就是循环神经网络的意义。
播单生成
在网络音乐推荐中,尤其是各类 FM 类 App,提倡的是一直听下去,一首歌接着一首歌地播下去,就很适合这些场景。
通常要做到这样的效果,有这么几种做法。
- 电台音乐 DJ 手工编排播单,然后一直播放下去,传统广播电台都是这样的。
- 用非时序数据离线计算出推荐集合,然后按照分数顺序逐一输出。
- 利用循环神经网络,把音乐播单的生成看成是歌曲时间序列的生成,每一首歌的得到不但受用户当前的特征影响,还受上一首歌影响。
Spotify 采用了第三种办法,下面我就详细讲解这个推荐算法。
1. 数据
个性化的播单生成,不再是推荐一个一个独立的音乐,而是推荐一个序列给用户。所用的数据就是已有播单,或者用户的会话信息。其中用户会话信息的意思就是,当一个用户在 App 上所做的一系列操作。把这些数据,看成一个一个的文档,每一个音乐文件就是一个一个的词。听完什么再听什么,就像是语言中的词和词的关系。
2.建模
你可以把播单生成看成由若干步骤组成,每一步吐出一个音乐来。这个吐出音乐的动作实际上是一个多分类问题,类别数目就是总共可以选择的音乐数目,如果有 100 万首歌可以选择,那么就是一个 100 万分类任务。这个分类任务计算输入是当前神经网络的隐藏状态,然后每一首歌都得到一个线性加权值,再由 Softmax 函数为每一首歌计算得到一个概率。表示如下:
假如隐藏层有 k 个神经元,也就是说 h 是一个 k 维向量,输出层有 m 首歌可选,所以是一个 One-hot 编码的向量,也就是说一个 m 维向量,只有真正输出那首歌 i 是 1,其他都是 0,那么输出层就有 k 乘以 m 个未知参数。
再往前,计算隐藏层神经元输出时,不但用到输入层的信息,在这里,输入层也是一首歌,也有 m 首歌可以选择,所以输入向量仍然是一个 One-hot 编码的向量。除此之外,每一个隐藏层神经元还依赖上一个时刻自己的输出值,隐藏层神经元是 k 个,一个 k 维向量。按照隐藏层计算公式就是下面的样子:
W 就是一个 m 乘以 k 的参数矩阵,U 就是一个 k 乘以 k 的参数矩阵。
如此一来,循环神经网络在预测时的计算过程就是:
- 当用户听完一首歌,要预测下一首歌该推荐什么时,输入就是一个 One-hot 编码的 m 维度向量,用 m 乘以 k 形状的输入层参数矩阵,乘以这个 m 向量,然后用隐藏层之间的 k 乘 k 参数矩阵,去乘以上一个隐藏状态向量,两者都得到一个 k 维向量,相加后经过非线性激活函数,比如 ReLU,这样就得到当前时刻的隐藏层输出值。
- 再用当前时刻的隐藏层输出值,经过 k 乘以 m 形状的输出层参数矩阵,得到一个 m 维向量,
再用 Softmax 把这个 m 维向量归一化成概率值,就是对下一首歌的预测,可以挑选最大概率的若干首歌作为输出,或者直接输出概率最高的那首歌直接播放。
这个计算过程示意图如下:
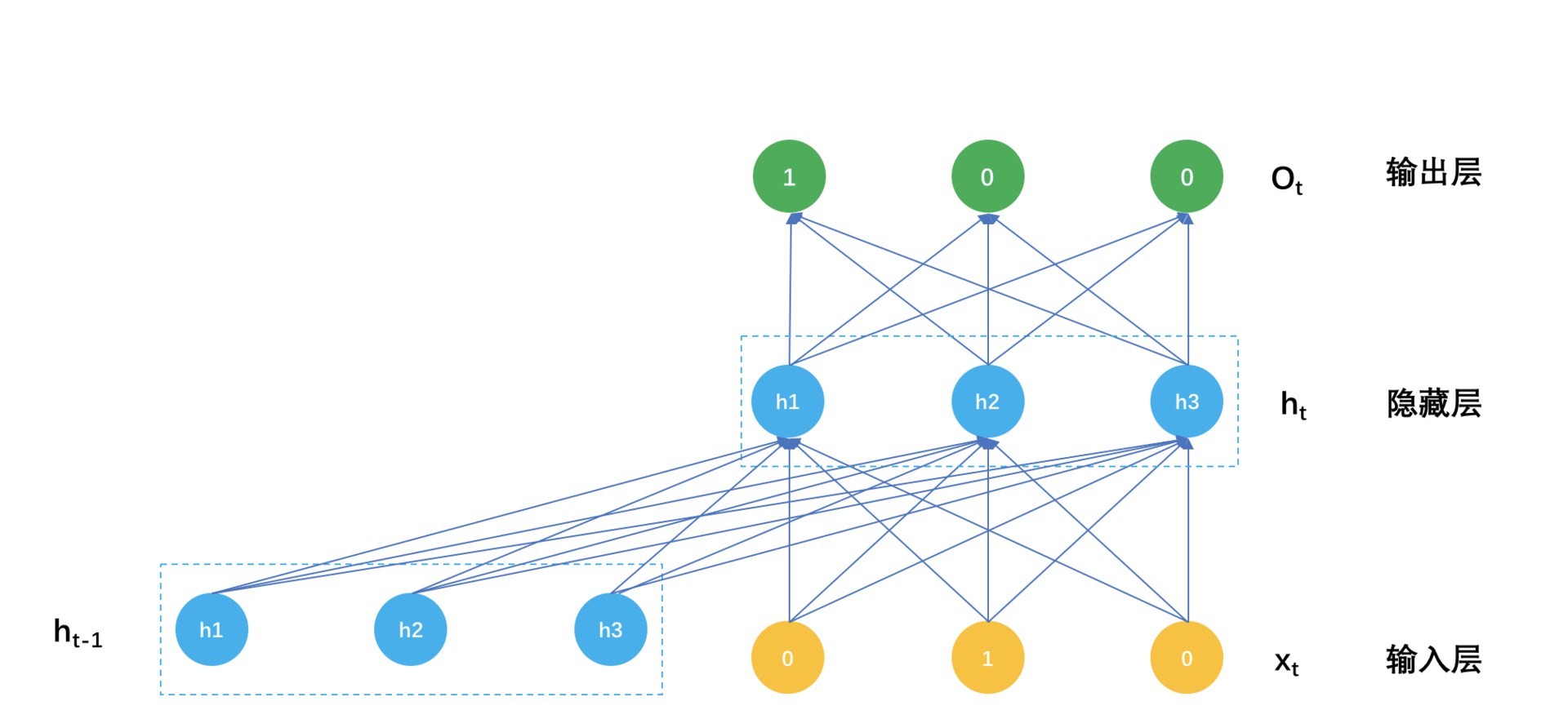
一个播单生成模型的参数就是这么三大块。
- 连接输入和隐藏之间的矩阵 $W_{m \times k}$;
- 连接上一个隐藏状态和当前隐藏状态的矩阵: $U_{k \times k}$;
- 连接隐藏层和输出层的矩阵 $V_{k \times m}$。
得到了这些参数,就得到了播单推荐模型,怎么得到呢?这里就再简要讲一下神经网络的参数如何训练得到。
- 初始化参数;
- 用当前的参数预测样本的类别概率;
- 用预测的概率计算交叉熵;
- 用交叉熵计算参数的梯度;
- 用学习步长和梯度更新参数;
- 迭代上述过程直到满足设置的条件。
神经网络中的误差方向传播,实际上就是链式求导法则,因为要更新参数,就需要计算参数在当前取值时的梯度,要计算梯度就要求导,要求导就要从交叉熵函数开始,先对输出层参数求导计算梯度,更新输出层参数,接着链式下去,对输入层参数求导计算梯度,更新输入层参数。交叉熵是模型的目标函数,训练模型的目的就是要最小化它,也就是“误差反向传播”的“误差”。