
1 引言
很多算法工程师认为 Embedding 技术是机器学习中最迷人的一种思想,在过去的近10年中,该技术在各个深度学习领域大放异彩。已经逐步进化到了近几年基于 BERT 和 GPT2 等模型的语境化嵌入。本文重点基于原始论文Efficient Estimation of Word Representations in Vector Space,整理 word2vec 相关技术的基础原理和应用经验,旨在利于自己回溯巩固和他人参考学习。
首先 Embedding 的思想是如何来的呢?我们知道计算机底层只能识别数字,并基于其进行逻辑等计算。而世间大多的实体或概念都不是以数据形式存在的,如何让计算机能够记住甚至理解是一件很难的事情。
如果我们能够将实体或概念以一种有意义的代数向量的形式输入给计算机,那么计算机对于它们的存储、理解和计算将会极大的友好。比如,对于一个人,如果我们重点关注他的性别、年龄、身高、体重、胸围、存款这些信息,那么我们可以将其记为以下形式:
[1,18,180,70,90,100]
其中每个维度的数值对应该维度的信息,也即性别=男(1)、年龄=18、身高=180cm、体重=70kg、胸围=90cm、存款=100W。当然你可以继续扩增更多的维度,维度信息越多,计算机对这个对象认识的更全面。
2 Word Embedding
在 NLP 领域,计算对于词的理解一直是一个很重要的问题。如前文所述,Word Embedding 目的就是把词汇表中的单词或者短语(words or phrases)映射成由实数构成的向量上,而其方法一般是从数据中自动学习输入空间到 Distributed representation 空间的映射 f。
2.1 One-hot
One-hot 编码又称独热编码,具体方法是:用一个N位状态寄存器来对N个状态进行编码,N是指所编码特征的空间大小。例如:
1 | gender:["male", "female"] |
这两个特征的每一个取值可以被 One-hot 编码为:1
2gender = [[1,0], [0,1]]
country = [[1,0,0,0,0], [0,1,0,0,0], [0,0,1,0,0], [0,0,0,1,0], [0,0,0,0,1]]
如此,One-hot 编码的优缺点还是很明显的。
- 优点:解决了分类器不好处理离散数据的问题,在一定程度上也起到了扩充特征的作用。
- 缺点:1. 不考虑词的顺序;2. 假设词之间相互独立;3. 向量是高度稀疏的;4. 容易出现维度爆炸。
2.2 Dristributed representation
根据One-hot的缺点,我们更希望用诸如“语义”,“复数”,“时态”等维度去描述一个单词。每一个维度不再是0或1,而是连续的实数,表示不同的程度。
Dristributed representation 可以解决 One hot representation 的问题,它的思路是通过训练,将每个词都映射到一个较短的稠密词向量上来。
例如,king 这个词可能从一个非常稀疏的空间映射到一个稠密的四维空间,假设[0.99,0.99,0.05,0.7]。那这个映射一般要满足:
- 这个映射是一一映射;
- 映射后的向量不会丢失之前所包含的信息。
这个过程就成为 Word Embedding (词嵌入),而一个好的词嵌入一般能够获得有意义的词向量,例如一个经典的case,即可以从词向量上发现:
2.3 Cocurrence matrix
一般认为某个词的意思跟它临近的单词是紧密相关的。这时可以设定一个窗口(大小一般是5~10),如下窗口大小是2,那么在这个窗口内,与 rests 共同出现的单词就有 life、he、in、peace。然后我们就利用这种共现关系来生成词向量。
… Bereft of life he rests in peace! If you hadn’t nailed him …
假设窗口大小为1,此时,将得到一个对称矩阵——共现矩阵,如此就可以实现将 word 变成向量的设想,在共现矩阵每一行(或每一列)都是对应单词的一个向量表示。如下所示:

3. word2vec
3.1 基本模型结构
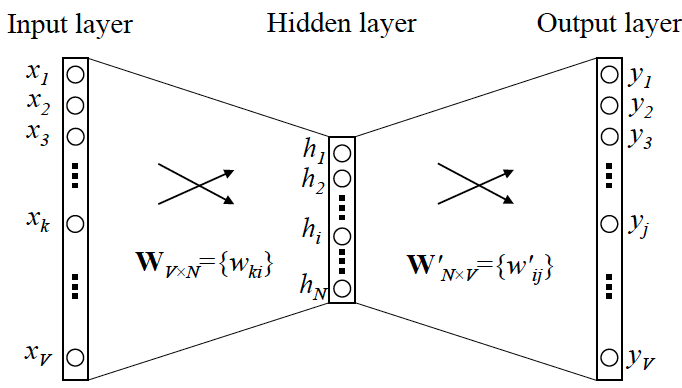
如上图所示,是 word2vec 的基本模型结构,其目的是:
利用单词本身的 one-hot 编码来完成的预测(即不同场景下的context),然后利用训练过程中映射矩阵中对应的向量来作为单词的表示。
简述一下上图的流程:
- 输入是 One-hot 编码,通过与映射矩阵$W_{V \times N}$得到隐层的行向量;
- 从隐层到输出层,有另一个映射矩阵$W’_{N \times V}$,与前面的行向量相乘得到输出向量;
- 之后经过 softmax 层,便得到每个词的概率。
整个过程用数学来表达就是:
其中 $ui$ 代表了输出向量中第 i 个单词的概率, $v{wi}$ 和 ${v’}{w_{j’ } }^T$ 分别代表了 $W$ 中对应的行向量和 $W’$ 中对应的列向量。
3.2 CBOW(Continuous Bags-of-word)
基于上述,我们来看一个经典的模型结构,CBOW,即连续词袋模型。与基准模型结构不同的是,CBOW 模型利用输入 context 多个词的向量均值作为输入。
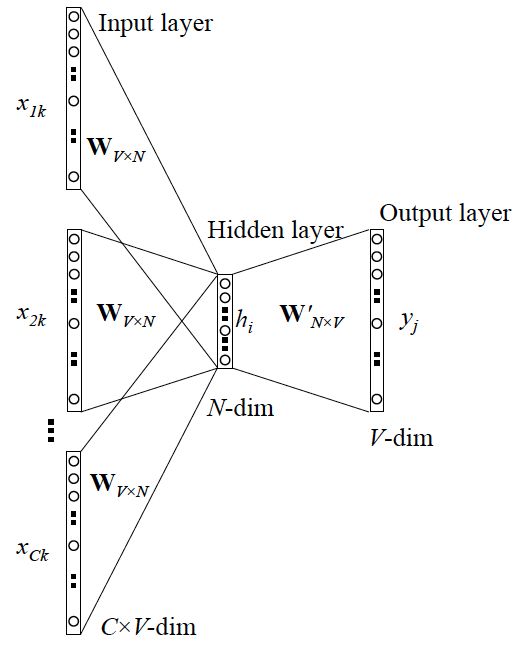
如上图所示,用数学描述即:
其中,C 为 context 的词语数量,所以CBOW的损失函数为:
3.3 Skip-Gram Model
核心区别:Skip-gram 是预测一个词的上下文,而 CBOW 是用上下文预测这个词,即 y 有多个词。
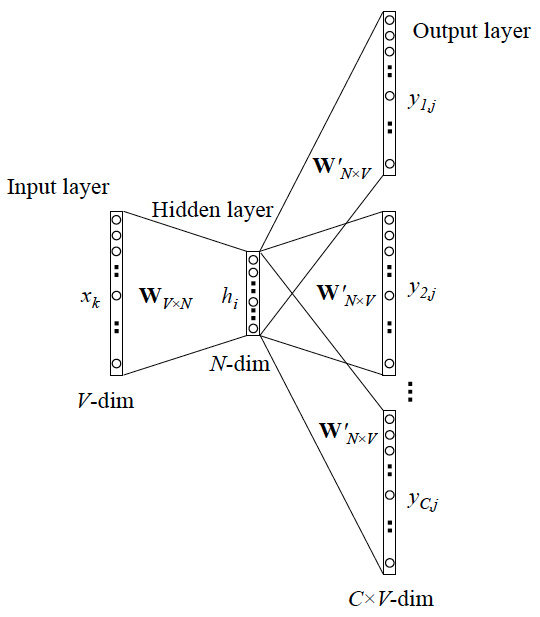
在传递过程中,其不再输出单个的多项分布(即一个词语的 one-hot 编码),而是利用共享的参数输出映射矩阵输出 C 个多项分布(此处 C 为context词语的数量):
其中:
- $w_{c,j}$是输出层第 c 部分中的第 j 个数字;
- $w_{O,c}$是输出 context 词中第 c 个数字;
- $w_I$ 是输入的唯一单词;
- $y_{c,j}$ 是输出层第 c 部分中的第 j 个单元;
- $u_{c,j}$是输出层第 c 部分上第 j 个单元的净输入。
由于输出时映射矩阵的参数共享,所以有:
在Skip-Gram中的 loss function 为:
4 输出层 softmax 优化
我们回顾 word2vec 算法,容易发现其在输出层为了预估词的概率,需要经过 sotmax 层。而,当词典空间很大的时候,softmax层容易成为整个算法的计算瓶颈。一般会有两种方法可以解决,Hierarchical SoftMax 和 Negative Sampling。
4.1 Hierarchical SoftMax
哈夫曼(Huffman)树是一种二叉树数据结构,基于其衍生的 Hierarchical SoftMax 能够有效地的降低 Softmax 的计算复杂度。我们首先介绍一下如何构建一颗哈夫曼(Huffman)树。
假设待构建的 n 个权值(一般是词频)为 ${w_1, w_2, \dots , w_n}$,可以通过以下步骤来构建 Huffman 树:
- 将 ${w_1, w_2, \dots , w_n}$作为森林中 n 棵树的根节点;
- 选取森林中根权值最小的2棵树,分别作为左右子树合成新树,且新根节点的权值为左右子树根节点权值之和;
- 用新合成的数替换森林中原来的2个子树,重复上述过程直至仅剩一棵树。
假设,有下面的一句:
I love data science. I love big data. I am who I am.
对应的词频表为:
| word | code | freq | bits |
|---|---|---|---|
| I | 10 | 4 | 8 |
| love | 110 | 2 | 6 |
| data | 010 | 2 | 6 |
| science | 11110 | 1 | 5 |
| big | 11111 | 1 | 5 |
| am | 011 | 2 | 6 |
| who | 1110 | 1 | 4 |
| . | 00 | 3 | 6 |
根据构建流程,实际上经过7次合并后完成 Huffman 树的构建:
- T1: (science, big) = 2
- T2: (who, T1) = 3
- T3: (data, am) = 4
- T4: (love, T2) = 5
- T5: (., T3) = 7
- T6: (I, T4) = 9
- T7: (T5, T6) = 15
按照上述步骤构建完成的Huffman树一般如下图所示:
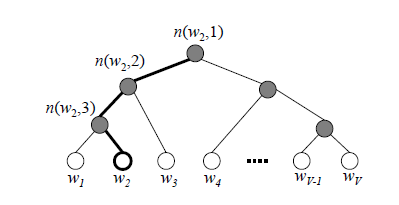
可以发现:每个词都为树中的叶子节点,即高频词计算路径短,低频词计算路劲长
剩下的步骤:
- 将每个节点的选择构建成一个简单的二分类问题(比如LR),这样每个词语输入节点时都面临一个二项分布的问题。
- 通过Skip-Gram中“一预测多”的思想,利用根节点的输入词来预测多个输出的叶子节点,这样每个节点输出的概率为对应路径中的多项分布概率相乘。
- 最后遍历词典中的所有输入,完成整个数的节点参数确定,最后利用每个节点路径上的概率来形成对应单词的隐向量。
由于在构建 Huffman 树的时候,保证了数的深度为 $log{|V|}$ ,因此在分层Softmax中只需做 $log{|V|}$ 次二分类即可求得最后预测单词的概率大小。
4.2 Negative Sampling
除了上述的分层Softmax方法,另一个更为经典和常用的便是Negative Sampling(负采样)方法。它的核心思想是:
放弃全局 Softmax 计算的过程,按照固定概率采样一定量的子集作为负例,从而转化成计算这些负例的sigmoid二分类过程,可以大大降低计算复杂度。
上述便是新的 Loss 函数,公式中前者是 input 词,后部分为负采样得到的负样本词。容易发现,网络的计算空间从$|V|$降低到了$|wO \cup W{neg}|$。而这本质上是对训练集进行了采样,从而减小了训练集的大小。
5 问题思考
5.1 负采样方式
算法的采样要求:高频词被采到的概率要大于低频词。
所以答案是非均匀采样,而是带权采样。
之所以如此,是因为在大语料数据集中,有很多高频但信息量少的词,例如”the, a”等。对它们的下采样不仅可以加速还可以提高词向量的质量。为了平衡高低频词,一般采用如下权重:
其中,$f(w_i)$是单词$w_i$出现频率,参数$t$根据经验值一般取$10^{-5}$。如此可以确保频率超过$t$的词可以被欠采样,且不会影响原单词的频率相对大小。
5.2 模型中两个embedding的取舍
在word2vec模型的训练阶段,一般创建2个词表矩阵,Embedding 矩阵和 Context 矩阵。它们的大小都是 vocab_size x embedding_size,其中 vocab_size 是词表大小,embedding_size 是词向量维度。如下图所示:
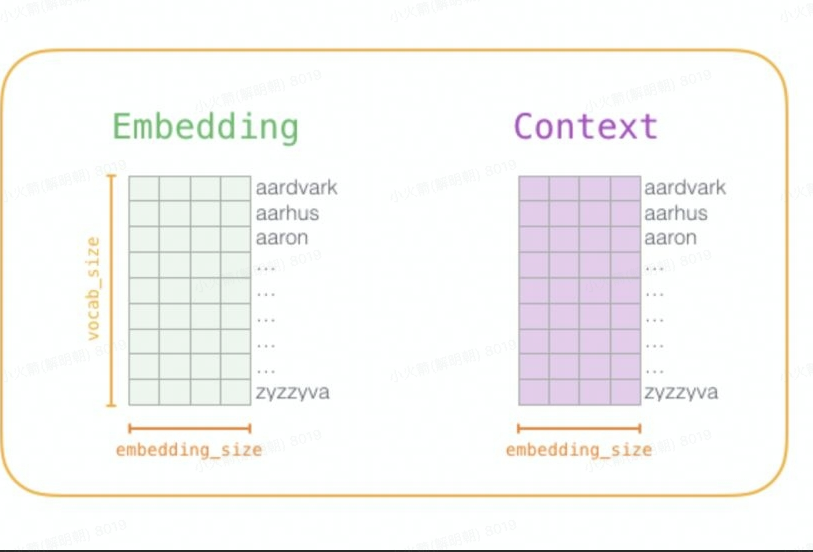
训练结束后,一般丢弃 Context 矩阵,并使用 Embeddings 矩阵作为下一项任务的已被训练好的嵌入。那为什么这么做呢?
在 Stack Overflow 上的问题Why does word2vec use 2 representations for each word?中有提到一个直觉性的解释,核心就是前者是中心词下的 embedding ,后者是 context 时下的 embedding ,他所表征的是两种不同的分布。
实际上,个人在实际应用中做了一些试错,这里记录共享一下:
- 使用中心词表 embedding 一定程度符合问题的定义:为了获取中心词 emb,从而采样 context 来构建样本训练的;
- 中心词和上下文词的 embedding 表都可以单独使用,但是不能交叉使用,比如2个近义词在两个独立词表中 emb 有意义,跨表 embedding 的关联性会失去;
- 从
CBOW和Skip-gram的算法逻辑看,中心词和上下文词 embedding 实际上是一个角色互换。
5.3 CBOW & Skip-Gram 的优劣
先总结一下结论:
- 当语料较少时使用 CBOW 方法比较好,当语料较多时采用 skip-gram 表示比较好。
- Skip-gram 训练时间长,但是对低频词(生僻词)效果好;
- CBOW 训练时间短,对低频词效果比较差。
对于上述的结论貌似业界较为统一,但是对于这个结论的原理解释众说纷纭,这里个人觉得下面这种逻辑分析更为合理。首先注意 CBOW 和 skip-gram 的训练形式区别:
- CBOW 是使用周围词预测中心词,周围词的emb表是最终使用的。其对于每个中心词的一组采样样本训练的 gradient 会同时反馈给周围词上;
- skip-gram 则相反,使用中心词预测周围词,中心词的 emb 表是最重使用的。那么中心词每组采样样本训练的 gradient 都会调整中心词的 emb;
如上情况,可能会认为两者虽然中心词和上下文词虽然角色不一样,但只是互换了位置,训练的次数和结果理应差不多。然而,当默认使用 embedding 词表的时候,情况是不一样的:
skip-gram 的主词表中每个 emb 的训练次数多于 CBOW 的。
因为,在 skip-gram 中,中心词的 emb 表是主词表,其每次会抽样 K 个上下文词,这保证了主词表对应的每个上下文词都训练到 K 次。
而 CBOW 则不同,因为其上下文词是主词表,中心词是用来训练上下文词的 emb,而由于采样概率的问题,虽然也会采样 K 个上下文词,但依然不能保证下文词对应的主词表的每个emb 都能够至少训练 K 次。
5.4 拓展应用
个人在实际工作和应用中,深刻的感受到 word2vec 的强大绝不止于预训练词向量这么简单,其算法原理的思想才是核心,可以应用在很多地方,也深深影响着我自己。
这里总结几个应用的场景:
- 最传统的便是nlp中文本词向量的预训练;
- 搜索推荐场景做 item2vec,可以用来输入精排或直接做向量召回;
- 召回/粗排模型样本的采样逻辑,如样本的负采样完全可以参考此逻辑。
参考文献
机器学习算法(十三):word2vec
Embedding知识点 —— word2Vec详解
word2vec对each word使用两个embedding的原因
图解Word2vec
NLP秒懂词向量Word2vec的本质
《word2vec Parameter Learning Explained》论文学习笔记